The purpose of this article
Multi-lingual Virtual Assistants’ capabilities are defined and documented in https://developer.kore.ai/docs/bots/advanced-topics/multi-lingual/building-multi-language-bots/
This article complements the above documentation and attempts to run through a real-time use case of enabling multiple languages on a bot with English as the default language and touches upon a few important NLU settings. This article also provides a few tips which may not be so clearly called out in the documentation.
First, let me give you a bit of context
Prior to 9.1.x, we had end-to-end NLP support for 20+ standard languages. Standard languages allow you to independently manage the NLU training and the responses for these languages. A separate NLU model is created for each of the enabled standard languages. You can also customize the responses for each of these languages.
In 9.1.x release, we have incorporated new methods- Input translation Method, and Multi-lingual model along with the standard model before. The developer can select one of these models.
With the use case and example below, I will touch upon these models.
Pre-requisites
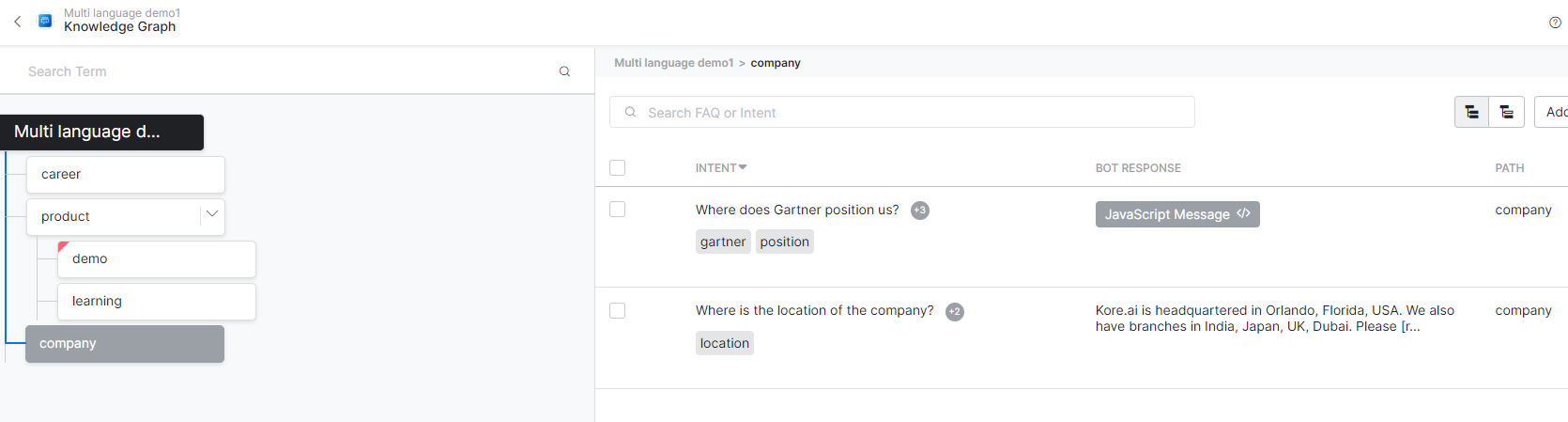
- A good starting point to create a multi-lingual bot on the Kore.ai platform is to have a bot which ready and is properly NLP trained. That means it has tasks trained with proper ML utterances, right bot responses, knowledge graph with the right ontology, etc.
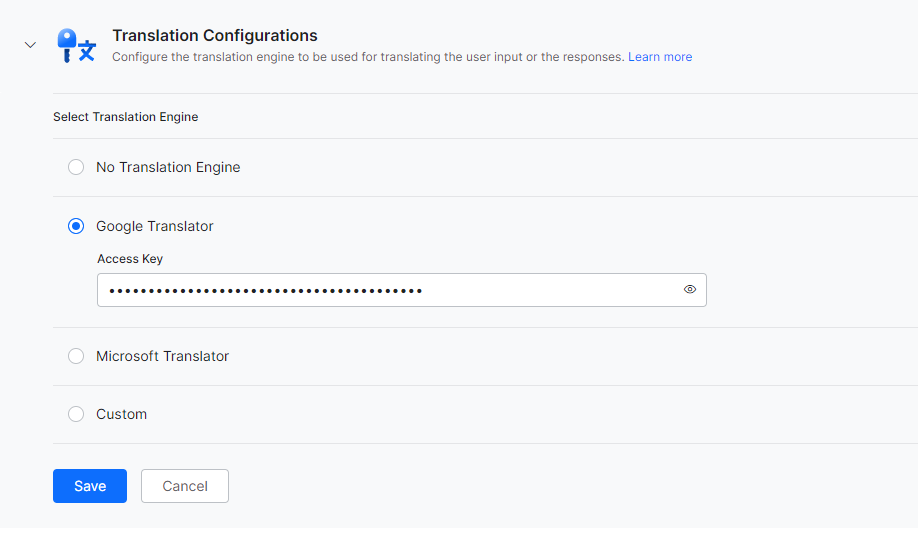
- Based on the NLU language chosen and your decision to enable auto-translation you may need an API key. Google API Key, Microsoft API Key (Global ONLY), and custom translation engines are supported. The effectiveness of the translation engines and keys should have been tested from generic tools or HTTP clients like Postman/cURL, etc.
- As per the current design, any new language enablement is an irreversible process. You may be able to disable the added language but the changes to the bot definitions cannot be reset.. A fresh backup of your bot should be taken. We recommend you to take a full back-up of both - published and in-development versions of the bot. You may consider placing the bot definitions in your code repository.
Ensuring the bot is ready for translation
- As described in the pre-requisites, please ensure the bot is functioning well and had adequate NLP training. In my example, my bot has a knowledge graph, dialog tasks, ML training, and patterns for the sake of simplicity.
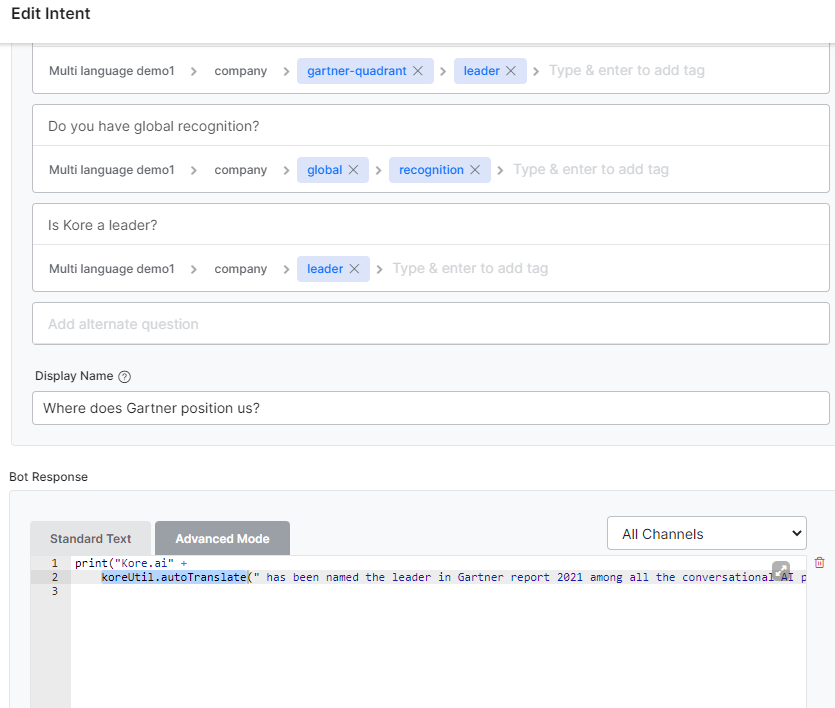
Note - If you have KG responses in JavaScript, it is better to use koreUtil.autoTranslate even before you attempt to add any language. NOTE - You will need a language translation engine set up (like Google Translate) with a working key to make this work. The reason will be explained further down in this article.
The same concept should be applied to the message nodes and entity prompts in the tasks wherever JavaScript is being used to print a response.
- As recommended in the pre-requisites, please ensure that the full bot backup (export) is taken.
Enabling a new language
- Navigate to the language management section of the bot.
- Add the Google/Microsoft translation API Key and Save. You also want to set up the custom translation. For the sake of simplicity, we will use Google API Key.
- I will keep the selection logic setting as per the message. This will enable the bot to check for a possible language change for every utterance. Please read the above-mentioned documentation link for more details on other options.
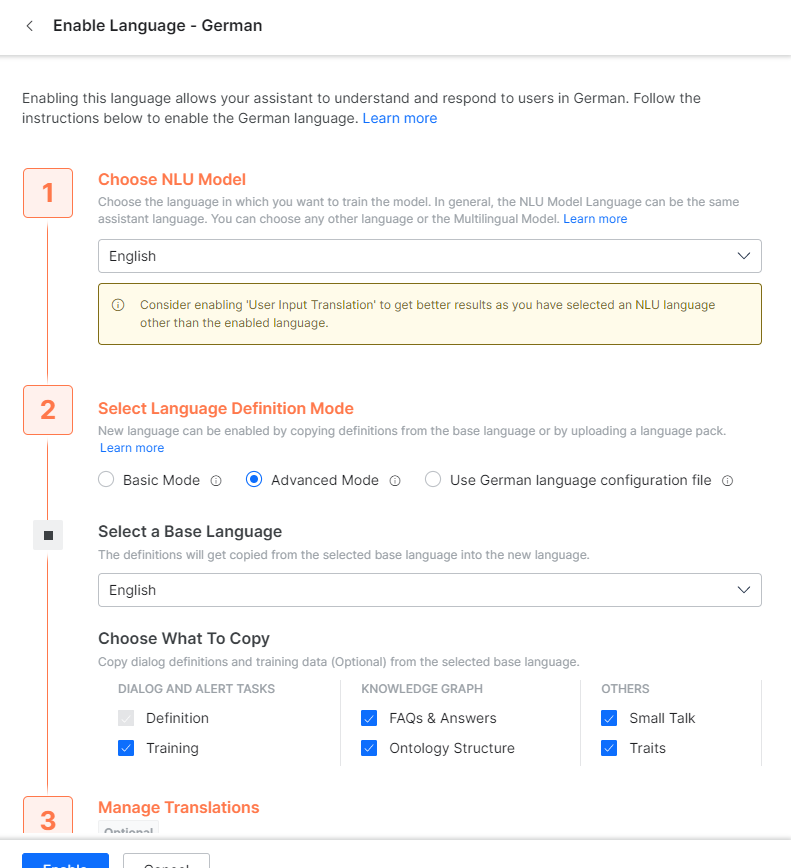
- Now click Add Language. I will add the German language and select English as NLU
- The concept of NLU can be thought of as the ‘first language’ or ‘mother-tongue’ of the bot. When a human with multi-lingual skills hears something in a language which he/she knows, they first subconsciously translate it into their native language and then try to process it to make sense of it. So, does the bot if you select an NLU language. Now when the bot senses the German language, the bot will first translate it into English and then try to match it with trained ML/pattern, FAQ, etc.
This is how NLU+input translation works at a high level
Translate the input to the NLU language → Process and analyze the in NLU language → Respond (If response translation is enabled, translate the response to the current user language) - Note that the language definition mode is a very important step. When adding a language, the bot creates ‘Language-equivalents’ of all the bot’s components - Dialog tasks, updated standard responses, ML training, etc. The default (non-customized) standard responses are a part of the system and not the bot definition.
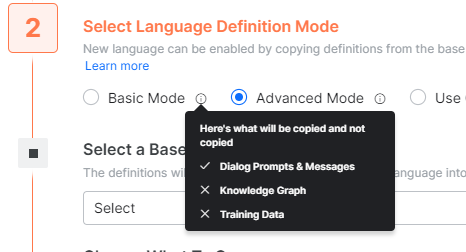
- For Basic mode, a language equivalent copy of ONLY dialog tasks and message nodes is created. Nothing else is copied over to the new language. The assumption is that the user wants to add their own training, FAQ, etc. for the new language.
- For Advanced Mode, as I have chosen (see above), you can select if you need other things like FAQ, their answers, Small-Talks, Training, Ontology, and Traits will be ‘copied’ to the new Language equivalent.
- It is important to note that these will ONLY be copied and not be translated during this step of enabling a new language.
- However, since the NLU language is English, for most of the cases the translation from German to English → Analysis by the NLP engine in English → Respond back - will work.
- What if I had selected German as the NLU language? In that case, the bot would look for German translations of the ML, updated patterns, and German FAQs in the German version of the bot. Since while enabling a new language, the messages, ML, etc will be just copied from the base language. Everything will need to be translated into German manually.
- I want my responses to be translated into the current non-default language, and I would not like to spend time translating them. So, I am using this option of ‘Enable Runtime Response Translation’ that will help auto-translate the bot responses. But please note, it works for plain text responses. For JavaScript response, the bot will need a proper usage of something like
koreUtil.autoTranslateas mentioned above. Without that, you may not see the responses getting translated.
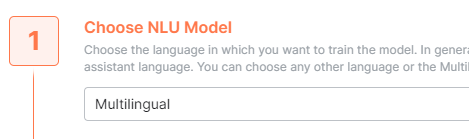
- A special note on Multilingual NLU language: In case, Multilingual is selected in the NLU model
the inputs are NOT translated. Multilingual is a vast collection of common user inputs and phrases in numerous languages. So, the bot will directly check against the multilingual database. This is the reason why with this NLU language, you will not get the option to auto-translate user inputs. It is not required.
This use case is typically for the organizations which do not allow their user utterances to go to third-party translators like Google/Microsoft/Others. So, with this setting, you will NOT need any API key.
However, you may choose to auto-translate the responses back. If you choose this setting you must have an API key. Otherwise, you will be required to translate the bot response manually.




Working with newly added language
- Now that I enabled the German language, the bot will -
- Copy the selected options (Dialog prompts, Messages - and ML Trainings, KGs, Small-Talks, Ontology, Traits, etc. as per the Basic/Advanced selection at “Select Language Definition Mode”) into German.
- You should see the new language you have enabled.
- When you select the new language - German, you will see the same dialogs and KGs as if nothing changed.
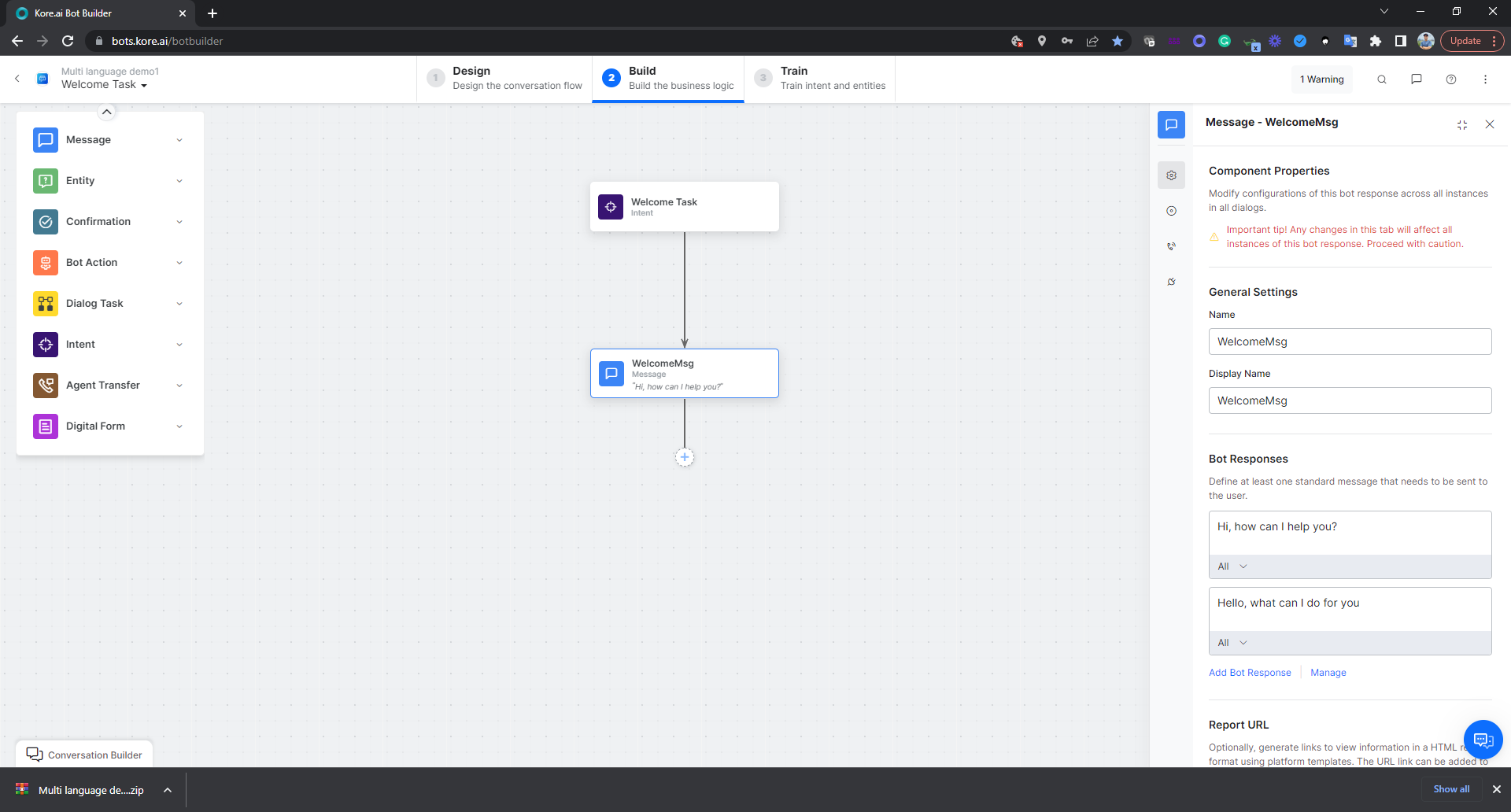
Even the welcome task will just be copied over. You will see English messages in the dialog task. It is expected.
- But when you talk to the bot (make sure the language is selected as German), the bot response will be auto-translated (provided the API key is correct)
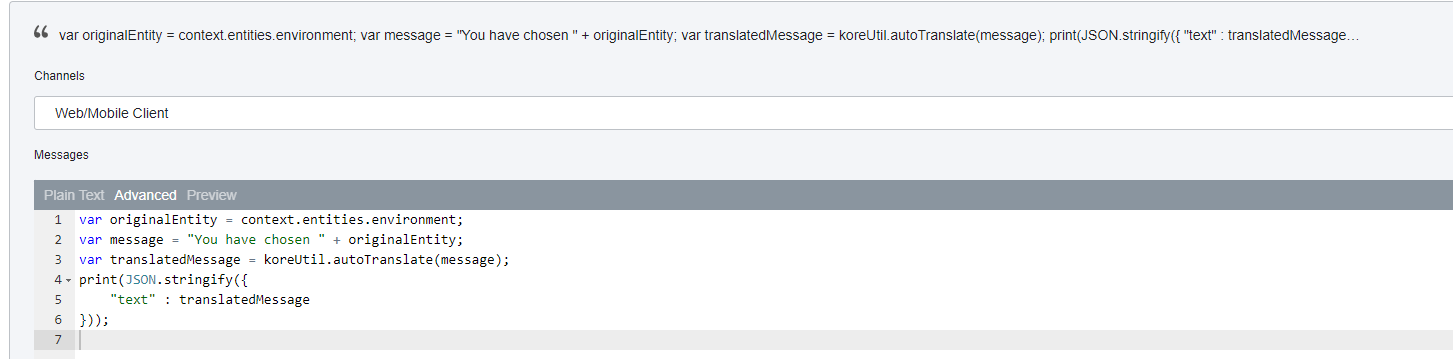
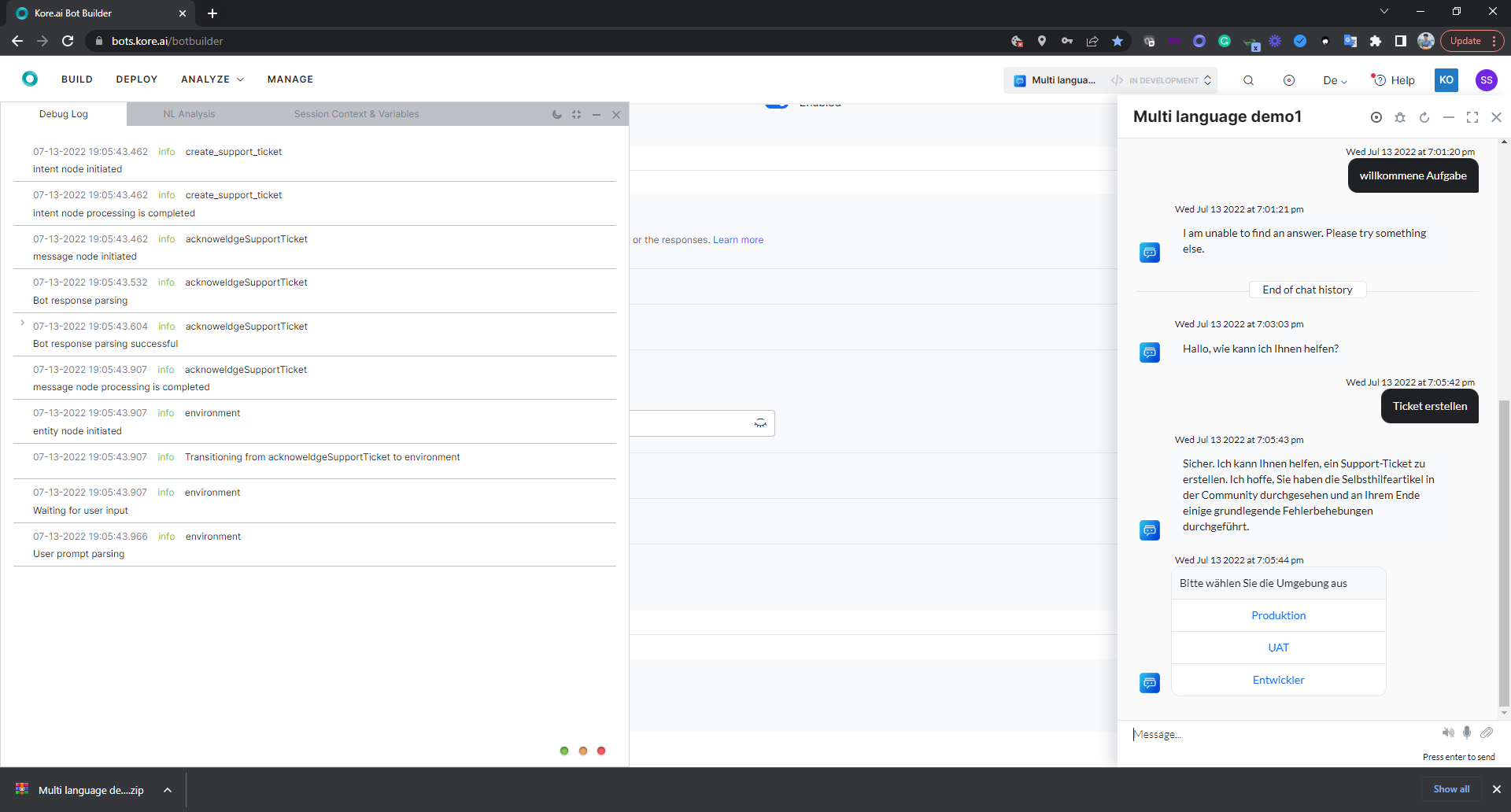
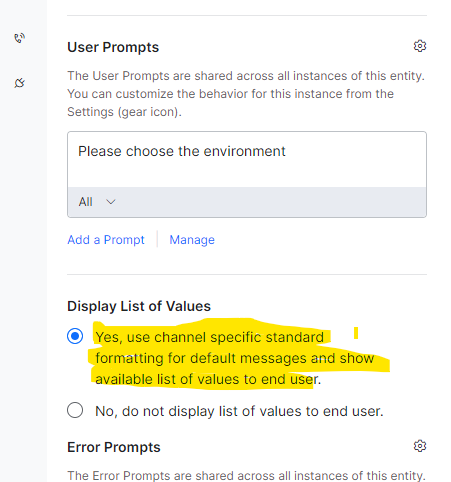
- Test: The utterance of ‘Ticket erstellen’ which is ‘Create ticket’ in English, is well understood by the bot. Now that the response is also auto-translated. The entity node uses automatic channel-specific formatting and translates the static LoV entity values. Had it been a JavaScript rendered template, I would have to use
koreUtil.autoTranslateas mentioned above.
- Before using the knowledge graph, one needs to select the German language.
Ensure training status is completed for the new language.
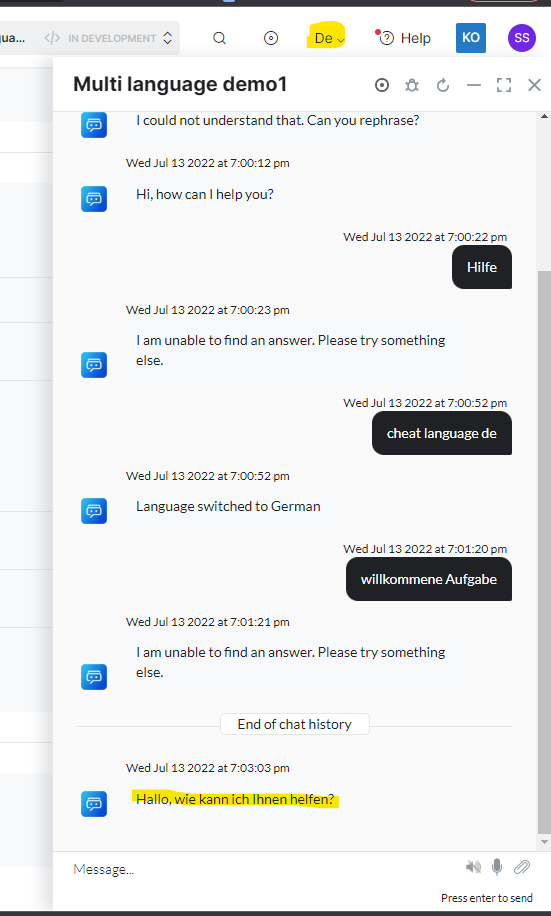
- There can be some cases, where, due to translation issues the right question or knowledge graph path may not be identified by the bot. For example:
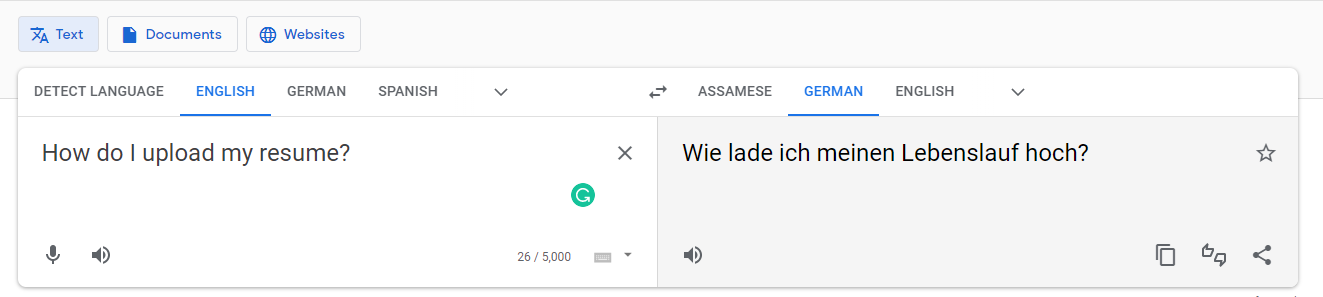
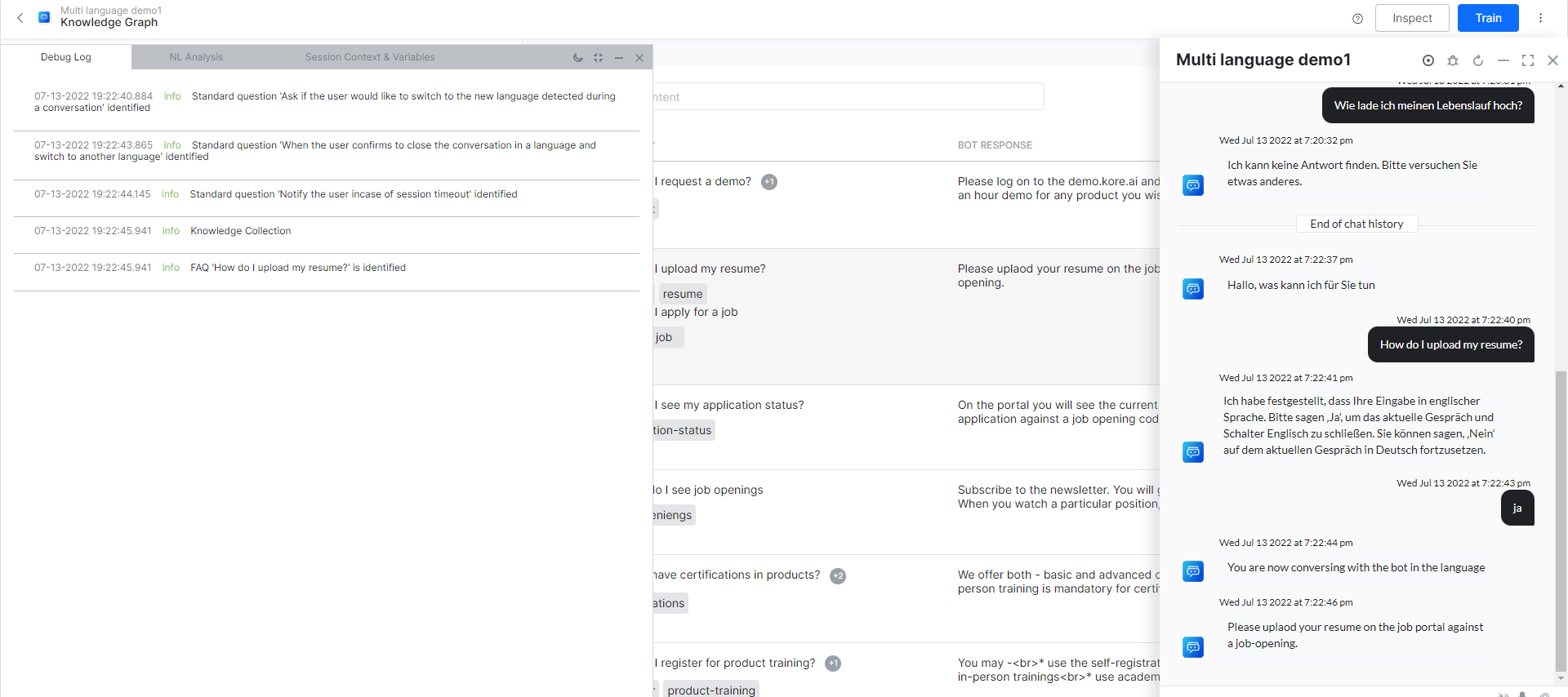
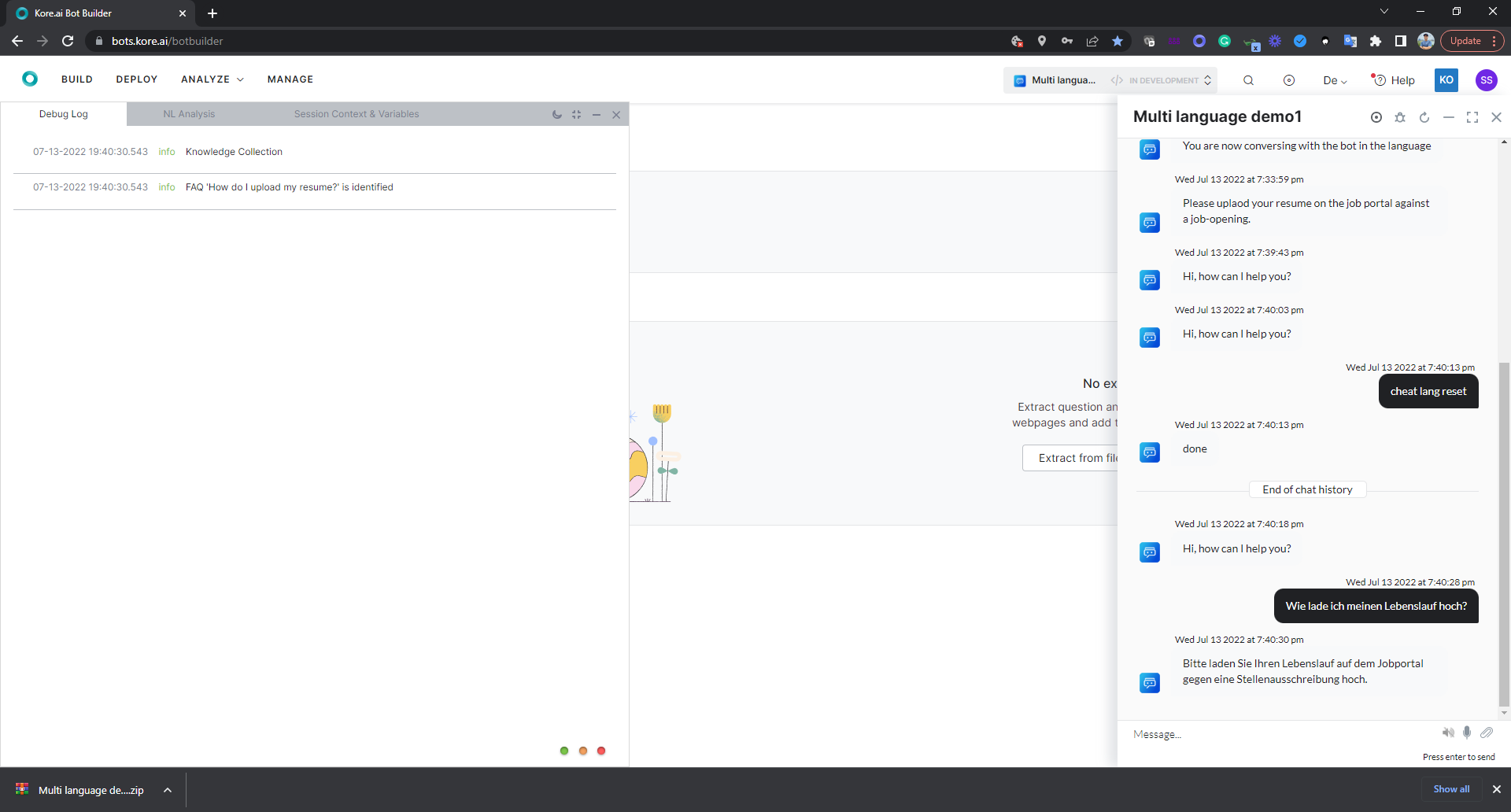
The English version of the bot understands ‘How do I upload my resume?’.
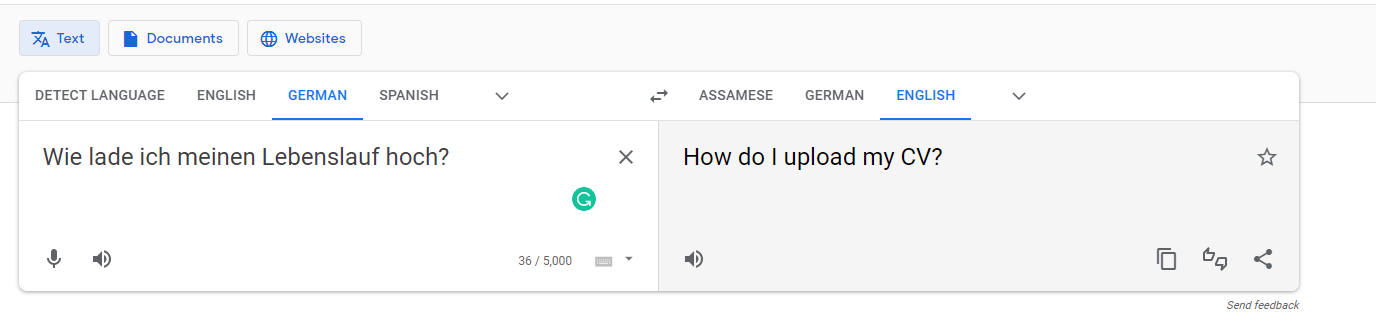
But when we use the German phrase is entered as an utterance, ‘Wie lade ich meinen Lebenslauf hoch?’ Google translates it back in English as ‘How do I upload my CV?’ and not exactly as ‘How do I upload my resume?’
The bot is unable to understand this because there is no path coverage for the term “CV”. This is a problem in the English version also. If I enter ‘How do I upload my CV?’ even the English version will not understand it straight away. So, let us fix it for English first. I go back to the English version of the KG and add a synonym ‘CV’ for the word ‘resume’. Initiating the training again is a must.
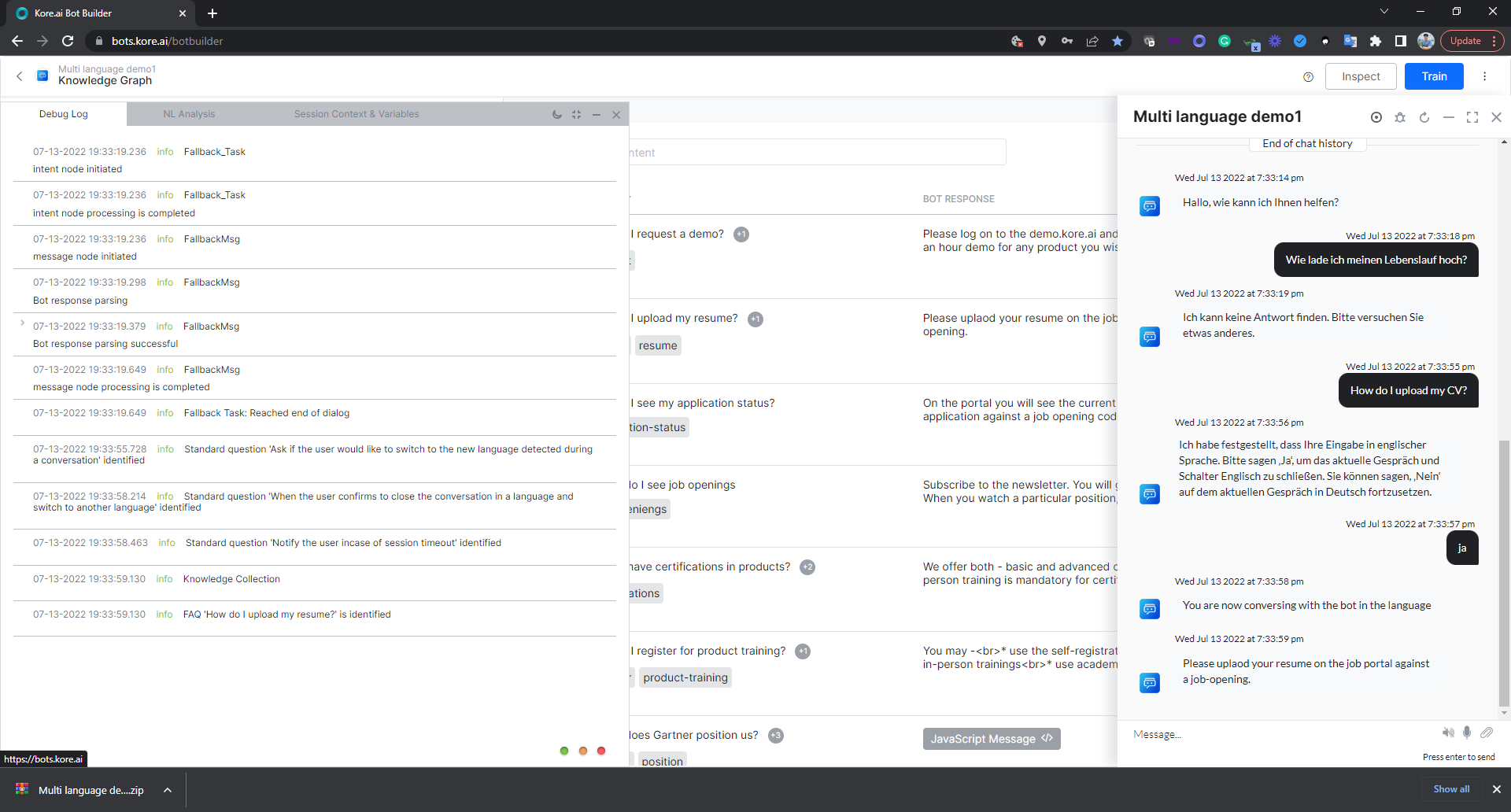
The bot would now understand ‘How do I upload by CV’ in English. But in German, the bot will not ‘Wie lade ich meinen Lebenslauf hoch?’ This is because the Bot refers to the German bot definition and the KG there was just copied over from English. Any change in English does not automatically sync with the German version. The KG in the English version is an independent insatance. So, is the KG version in German. For every language, a separate KG version is maintained and referred to.
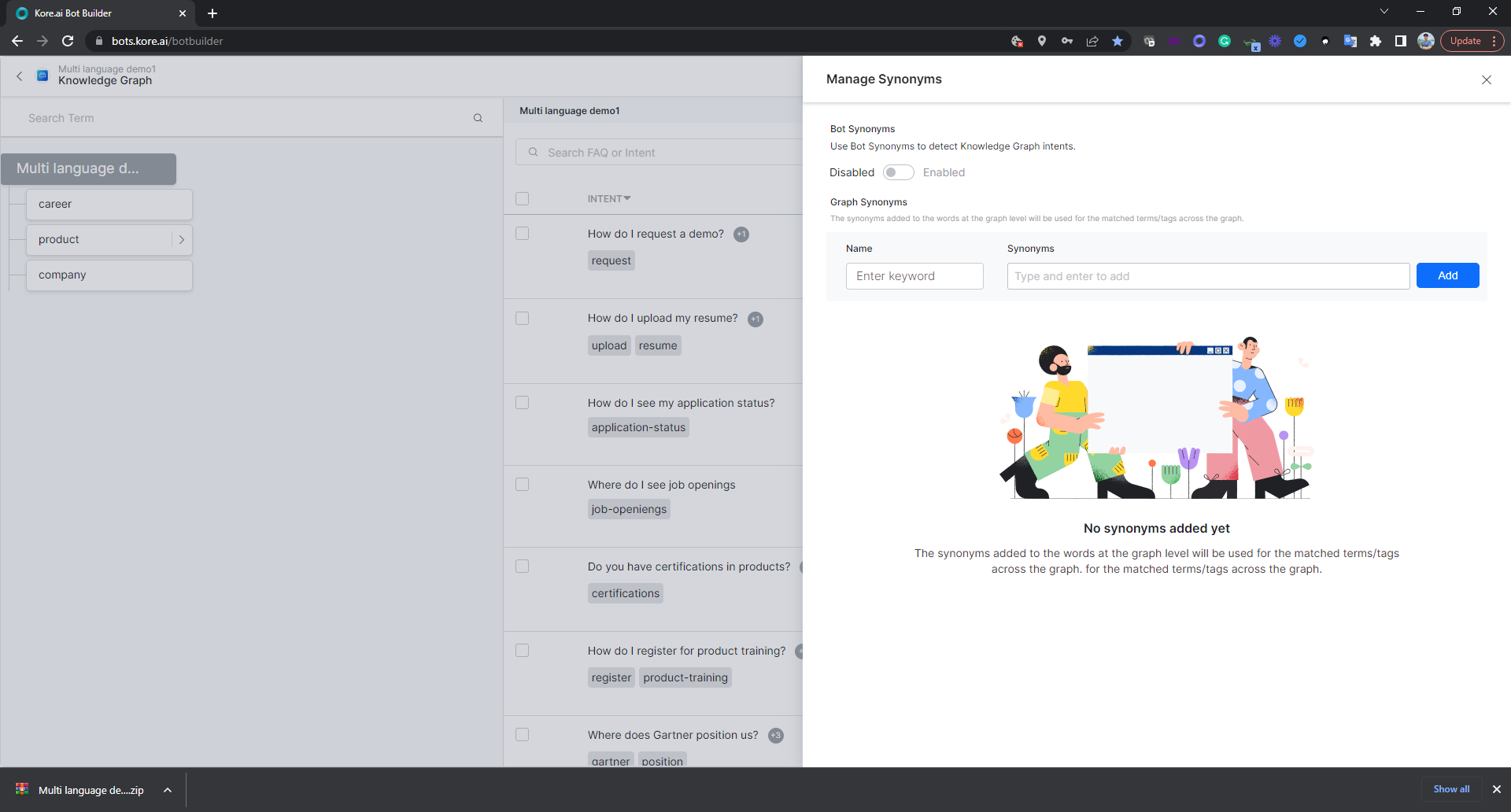
When I select the German version and navigate to the knowledge graph, I see that there is no synonym of ‘resume’ as ‘cv’ at the KG level.
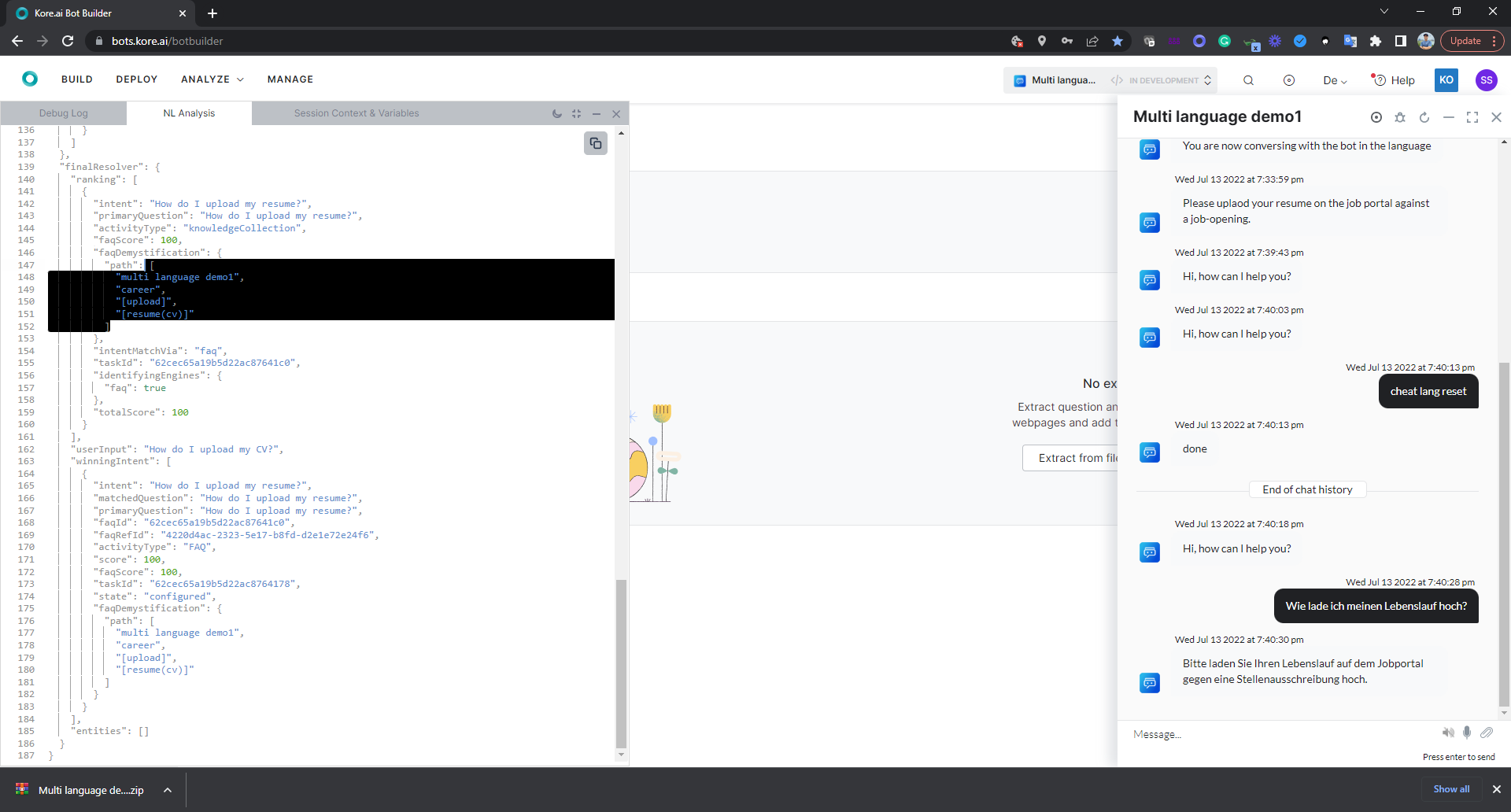
It may need some tweaking to fine-tune the KGs. Here if I add ‘cv’ as a KG synonym for resume, and train the bot (while being in the German version), it works.
The NL Analysis finds the right path.

- It is to be noted that for any language-specific KG changes, only the language-specific KG gets updated. Any change to English KG does not automatically reflect in the German version and vice versa.
- For properly training the KG, the bot language has to be selected from the UI → Then the user needs to navigate to KG and initiate Training.
Some other things to keep in mind while working with NLU-based automatic language translations and language enablement:
- As mentioned above, just re-iterating that the JavaScript-based responses may need to be revisited in your bot post translation if you have not used
koreUtil.autoTranslatealready (As stated above this needs the translation engine set up using a working key - like Google Translation key). - The more the number of languages, the greater will be the time taken for the bot to complete a training request. So, try not to enable too many languages at the same time. If you are trying to add more language capabilities to the bot, you may add a language and keep other languages disabled during development.
- Patterns are treated as very specific inputs and by design, the intent/KG identification against a given pattern is very rigid. So, language-based changes may/will need to be done. In the above example, if I had a pattern with “resume” to identify a task/KG, adding a synonym “CV” would not have helped. I would have to adjust the pattern specific to the language.
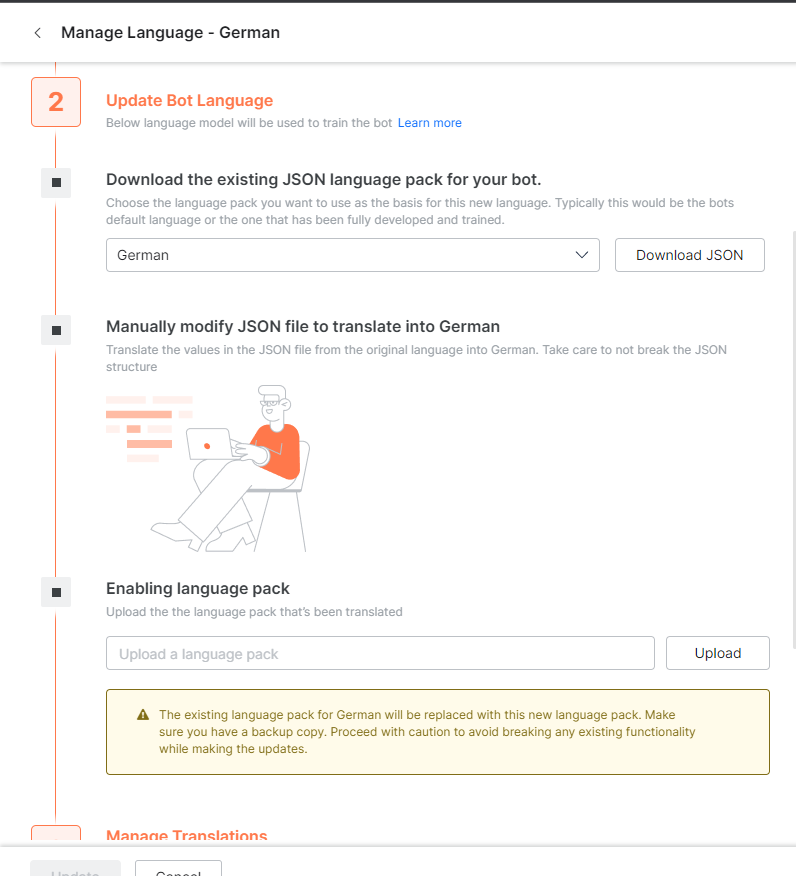
- If you want to manually translate the bot training, responses, etc. in bulk, the platform offers a functionality wherein you can download the ‘language’ version of the bot in JSON → Make edits externally (maybe engage a language specialist or vendor) → Import the JSON.
Here you can download the current responses and training of the German language JSON, edit it externally and translate it as needed, and then import it back.
Once all the bot responses are properly translated, you may want to disable auto-translating the bot responses to save costs.
Note: This does not include the KG.
- The bot may have difficulty identifying mixed language inputs - “English + Chinese”, “English + Hindi” etc.
- As soon as the language is switched to a new language, the context will be cleared. So, any stored values in the context will be lost.
- The NLP engine will ask for a confirmation before switching the language. If no confirmation is taken, inadvertently the context may be lost.
- For Multilang NLU, the FAQ term types - Default and Mandatory are not honored. You can only use Organizer nodes to organize the FAQs. So, the FAQ hierarchy and ontology are pretty much flattened. Assume that you add the Polish language and select Mutilang as the NLU language. You had the English FAQs copied to the Polish version. Now any FAQ that is asked in Polish will very much depend on the translation and if the translation does not provide the Kore.ai platform with the exact translation that is required to honor a mandatory node, the system will not be able to find the KG. So, for a better success rate for finding the KGs, as per design, the Multilang NLU does not honor the term types set in the KG.

Conclusion
- We are always trying to improve things, provide a seamless experience to the users, and reduce the efforts needed to add a new language capability to the bots.
- However, every language is unique and has different grammar, rules, and a huge number of possibilities that need to be handled. So, sometimes, adding a language simply may not work for 100% of the use cases and some minor modifications might be required.
- This article targets to make the users aware of some of the NLP features and constraints as of date. The NLP capabilities will most likely change and improve in the future.
Courtesy - @swagata.sengupta @venkata.mutnuru @sitaram.kanakamedala