What is NLP Accuracy?
It is the ability of the Chatbot to understand the correct intents for a given input. The intents can be trained using below ways
- FM Engine
- ML Engine
- KG Engine
- Traits Engine
Which Engine to use When?
- Do I have a large corpus for each intent I am planning to implement? [Machine Learning]
- Definition of “a lot” could change depending on the intents. Ex: If all the intents are very different from each other (can be understood using their sample data), then a corpus of 200-300 for each intent is sufficient. However if intents could be closer to each other ex: Transfer funds vs Pay bill (they have very similar utterances), then usually we need 1000s.
- If we are planning to use Deep Neural Networks, they are data hungry and higher the number of samples, better the predictions of both True Positives and True Negatives.
- Do I have a lot of Intents but I do not have time to prepare lots of alternate utterances, but I am ready to manually annotate some important terms? [Knowledge Collection]
- Are my intents more of Questions than Transactional multi-turn tasks? [Knowledge Collection]
- My Content is in Documents and I want the Bot to answer user queries from documents? [Knowledge Collection]
- Do I have cases where users could use idiomatic sentences or command like utterances? [Fundamental Meaning, use patterns]
- How strict do I want to be? Is it ok if there are some false positives? [Fundamental Meaning, add patterns to FM engine]
- Vague utterances, dependent on contextual information? [Traits Engine, refine in default dialog]
How can we measure?
The metrics used to measure the NLP accuracy are
- Accuracy
- Precision
- F1 Score
- Recall
The model which has higher Recall is the best NLP model. Any machine which is trained with 90% accuracy, still may fail in the real world. It is essential in the first few days of deployment, get the feedback about real user utterances into the development and testing.
It is always better to not to identify any intent than identifying wrong intent. Conversation should be designed properly to handle these user utterances using Default dialog in the Kore XO platform. It is a perfectly natural part of conversation to ask for clarifications.
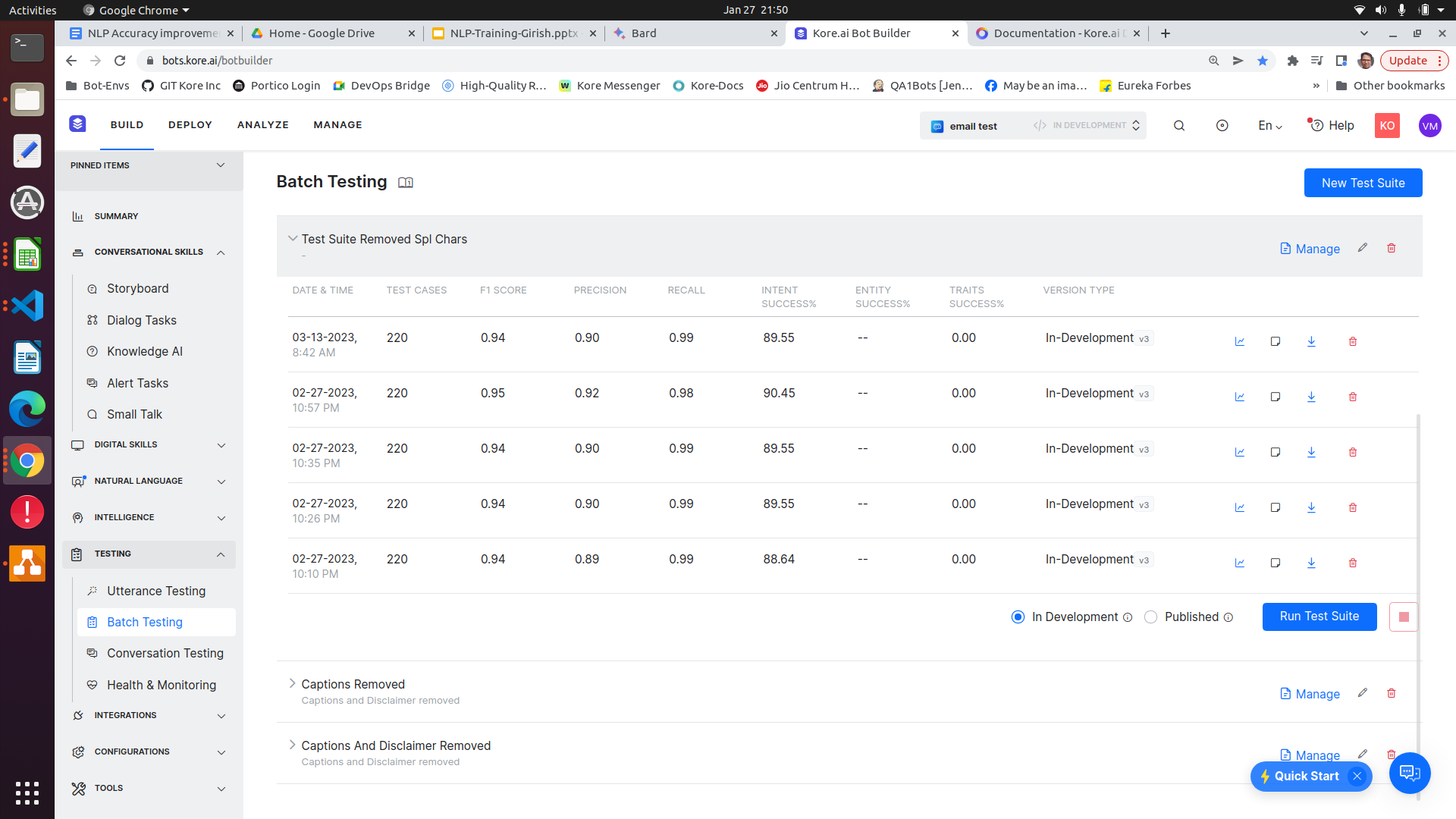
Kore XO platform provides the feature “Batch Testing” to capture these metrics.
Create batch test suites and execute them to identify the metrics. Multiple batch test suites can be created and executed multiple times (Certain limitations are there, only one batch test can be executed at once). Once the batch test suite execution is completed, a simple execution report will be generated and shown.
From a Bot development perspective it is recommended to create the batch test suite (or several) first before adding training. Test Driven Development allows developers to track progress. Also recommended that test utterances are generated and sourced from different people than the NL trainers. Everyone has their own biases and specific ways of phrasing. It is important to capture a large range and variety of utterances.
Recommended to include batch test utterances that are initially out of scope for actual intent identification, they would have “None” as their Expected Intent. Need to know if there will be false positives, and users will not know what the Bot does not know.
The more test utterances the better, a 90% score from 1000 utterances offers much more confidence then 90% out of 10 utterances.
Utterance testing is useful for quick checks and exploring the details of a specific match.
Challenges with NLP Training data
- Availability of high quality labeled training data
- Availability of good quantity of the labeled training data
- Good distribution of training data across different dialogs. If one dialog has more training data than the other, the model tends to skew.
- Training data balance - common vocabulary/phrases should be evenly distributed
- Overlapping training data across similar business function dialogs / intents (Payment update vs Payment update status)
- Clear understanding and purpose of each intent
To address the issues with Training data refer to kore.ai developer documentation link
Challenges with NLP Accuracy
- False Negatives: For a given input, nothing was identified
- False positives: For a given input, different dialog / intent was identified other than expected intent
- Ambiguities: For a given input, additional intents along with expected expected intent
How to improve the accuracy?
Is it really a tough job? Yes it is. NLP accuracy improvement is not a one step movement. It is a journey and iterative process. It involves not just technical knowledge, but also requires the business importance of each of the dialogs and the relationships between those dialogs.
Kore.ai platform provides all the tools and utilities you need to analyze and improve the accuracy of the NLP.
First things first. Identify whether the training data is properly mapped to the desired intents or not.
Execute the “Developer defined utterances” batch test suite
-
This test suite validates the utterances that have been added and trained by the developer from the Machine Learning Utterances screen.
-
Use this result to measure the training data mapping to correct (desired) intents.
-
An intent accuracy of 100 means that the training data is correctly mapped to the intents.
-
If there is any drop in the accuracy,
- Identify the intent(s) which have been wrongly identified.
- Fix the training data (Add, remove, modify) the training data in the identified intents.
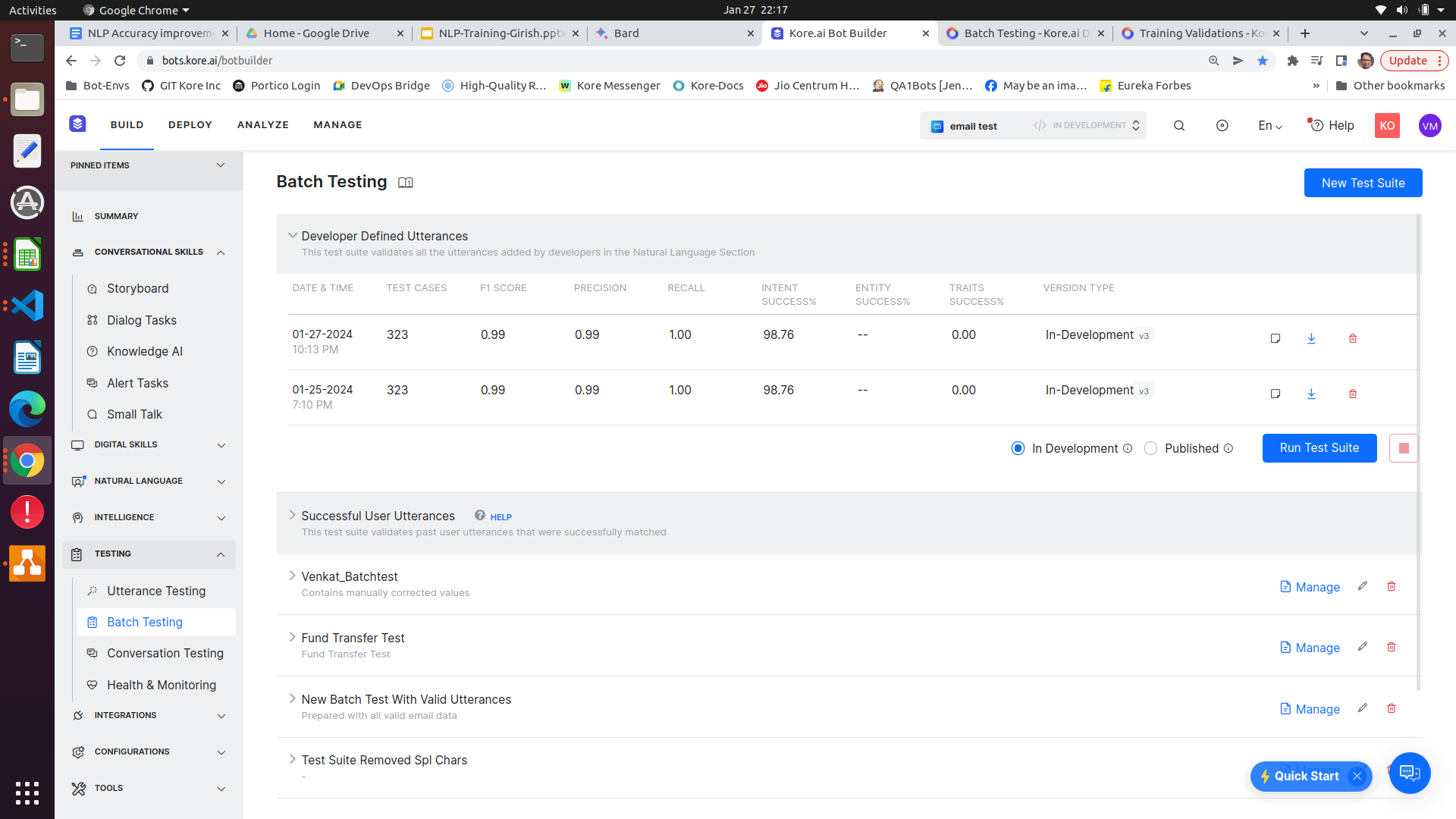
Example:

In the above hypothetical scenario two intents “matured loan closure” , “account closure” are causing the failures. Hence the training data is very close in both these intents. Hence suggested to revisit the training sample in both these dialogs and modify the training.
Fix False Negatives (FN)
Typically low hanging fruit in the journey of NLP accuracy improvements as it generally signals missing training data Identify all the test utterances for which no intent is identified.
One alternative FN scenario is where ML training for several intents overlap and effectively cancel each other out, producing scores that are below the required threshold. An ML process is a zero-sum game, so if one intent “wins” then another “loses”.
Finally a FN may indicate a missing intent if the training data is considered complete.
Add (or remove) the training utterances in ML engine or Patterns or a missing word in a concept for the FM engine. Train the model, re-execute the batch test.
FN for KG intents can indicate several things:
- Too many path terms that make it hard to reach the path threshold
- Not enough variation in questions to have a good similarity match
Fix False Positives (FP)
This is the toughest part in the NLP accuracy journey. Fixing False Positives requires thoughtful evaluation of training data, business function knowledge. It is important to consider whether the training data is correct or the test data is correct. This is a manual activity
- Approach 1:
- First check whether the expected intent is correct or not. In some scenarios, it has been observed that model predictions are correct. This requires business function knowledge.
- Identify the actual intents which caused most False Positives. (Set 1)
- Identify the expected intents from the above set which failed more. (Set 2)
- Validate the training data of actual intent (FP) against expected Intent
- Experiment with different phrasings of the utterance to discover which are the key words that influence the outcome. Helpful to add those variations to the batch test suite
- Modify / Remove the training data from actual intent (FP) which is matching with expected intent
- Add training data to expected intent to give it a “boost” with respect to the actual intent.
- For KG, evaluate the terms in the path, the best set would be those that uniquely identify the intent
- Add negative patterns to an intent, though it is preferable to improve positive training rather than rely on negative patterns
- Train the model and re-execute the tests.
- Please note that this is a repetitive process until we get the desired FPs addressed.
- Approach 2:
- Use NLP utterance testing for demystifying the identified intent
- Verify the elimination reasons.
- Check for ML score of the expected intents
- If predicted intent is a possible match from ML, Add pattern(s) to expected intent
- If predicted intent is a definite match, identify the possible negative patterns to eliminate the intent. (This must be the last option)
Fix Ambiguities
Ambiguity resolution is one of the most important NLP activities in the conversation ai development. In the world of latest embeddings based NLP models, It is not uncommon to have ambiguities for a given input for 2 differently functioning business cases.
E.g, “I wanted to block my card” vs “I wanted to unblock my card” are very similar, the similarity score will be very high (~0.87)
In the business functionality “Block Card” and “Unblock Card” are diagonally opposite to each other. Handling these kinds of ambiguities requires a tactical approach and a technical approach.
- Augmenting training data (technical approach). This is not a simple task because it requires to train, validation with a lot of training samples to differentiate the overlapping intents. This is an iterative process and time consuming activity.
- Define the conversation experience (Tactical approach). This requires knowledge of the business importance of each of the identified intent.
Define conversation experience
-
There could be business rules which prioritizes one intent execution over another.
- E.g, if the ambiguity occurs between “Open account” vs “Close account”, it is always preferable to ignore the “close account” intent because It is not good to lose a customer.
-
Even though ambiguous intents are identified, there could be the required intent is more similar with user utterance than the other identified intent
- E.g, For instance, input “I wanted to block card” scored “~0.98” with “Block card”, while scored “~0.95” with “Unblock card”
- Using the score, Bot developers can determine which intent can be executed.
-
Kore XO platform provides a feature to handle ambiguous intents. Configure the ambiguous intents events as shown below
-
The identified intents can be accessed in the dialog by using koreUtil.getAmbiguousIntents()
-
Please refer to below documentation links
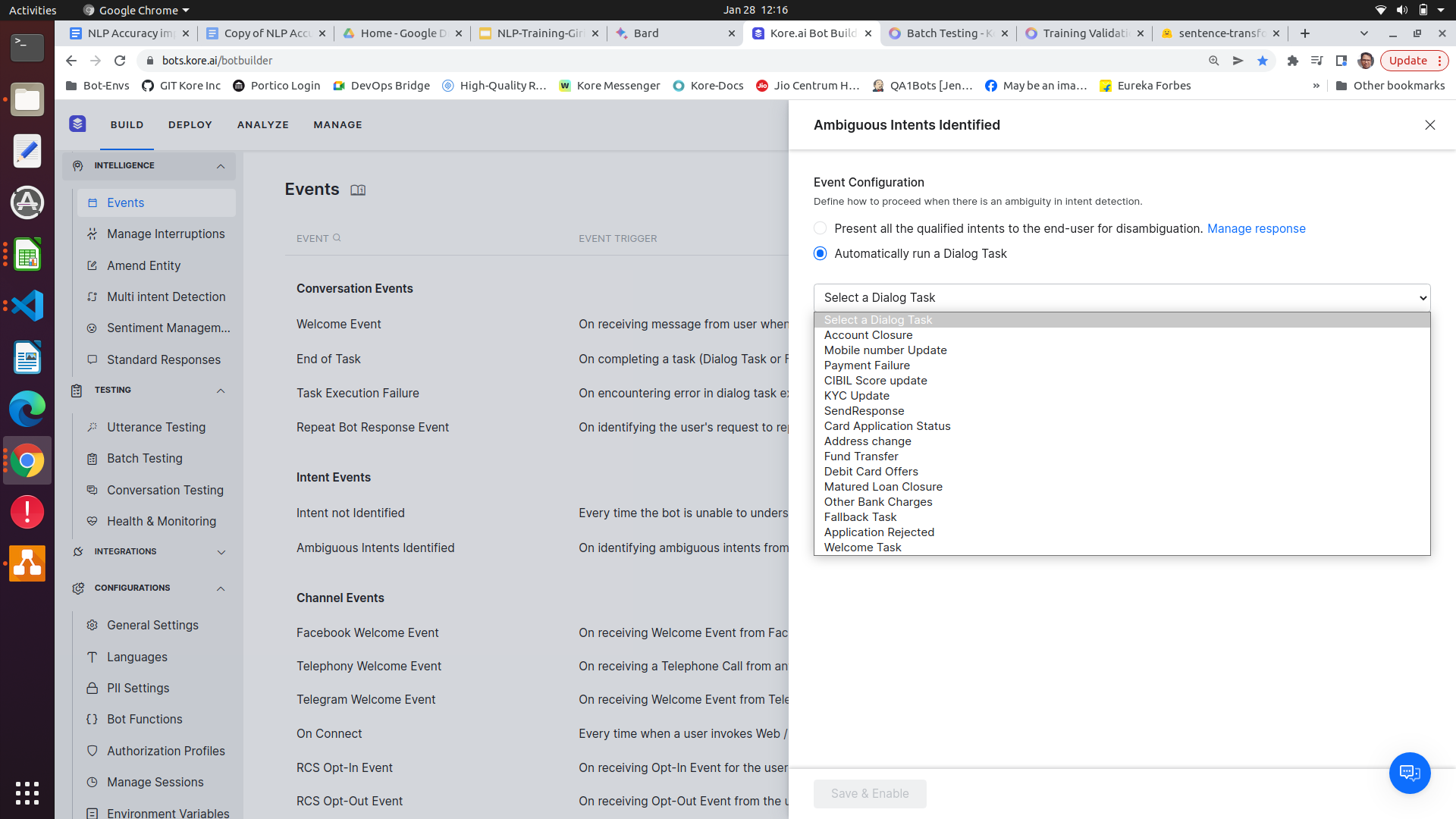
(Search for Ambiguous Intents Identified Event)
Augment training data
- Augment your dataset with sentences that explicitly differentiate between “block card” and “unblock card” in various contexts. This can involve adding examples like “I need to block my credit card due to fraudulent activity” and “Please unblock my debit card as I made a mistake.”
- Add more positive training data to respective intents
- Check for Thresholds value for Definite, probable matches and adjust accordingly
- Check for Proximity thresholds as well which influences the winning intents.
- Add negative patterns for the intent which requires to be eliminated. Please use this as a last option only.
- Train the model and validate the tests.
Remember this is an iterative process and time consuming activity.
Best practices
- Always follow the test driven approach. Define all the possible test scenarios the bot needs to cover.
- Never use One word training for ML. If this is highly required, it is suggested to define patterns.
- Consider the option of enhancing None Intent training with FAQs and other out of vocabulary specific sentences
- Remember ML does not have a mechanism to enforce a match against any particular word, unlike FM and KG. Every word in the ML Training generates some form of association to the intent. Therefore be careful when adding sentences and do not include phrases that are unconnected to the intent.
- Be careful with ML stop words. Every word in a language does have a purpose, however small, and those differences can be the difference between a true and false result. For example, common prepositions are attached to verbs (to form phrasal verbs) that form specific meanings, “write to someone”, “write about someone” and “write on someone” all mean dramatically different things.
- Please explore the option of Entity place holders at both design time and run time. However this needs to be considered carefully.
What could go wrong with Entity placeholders, A real world use case
Tagged NER to the single-word ML utterance as shown below.
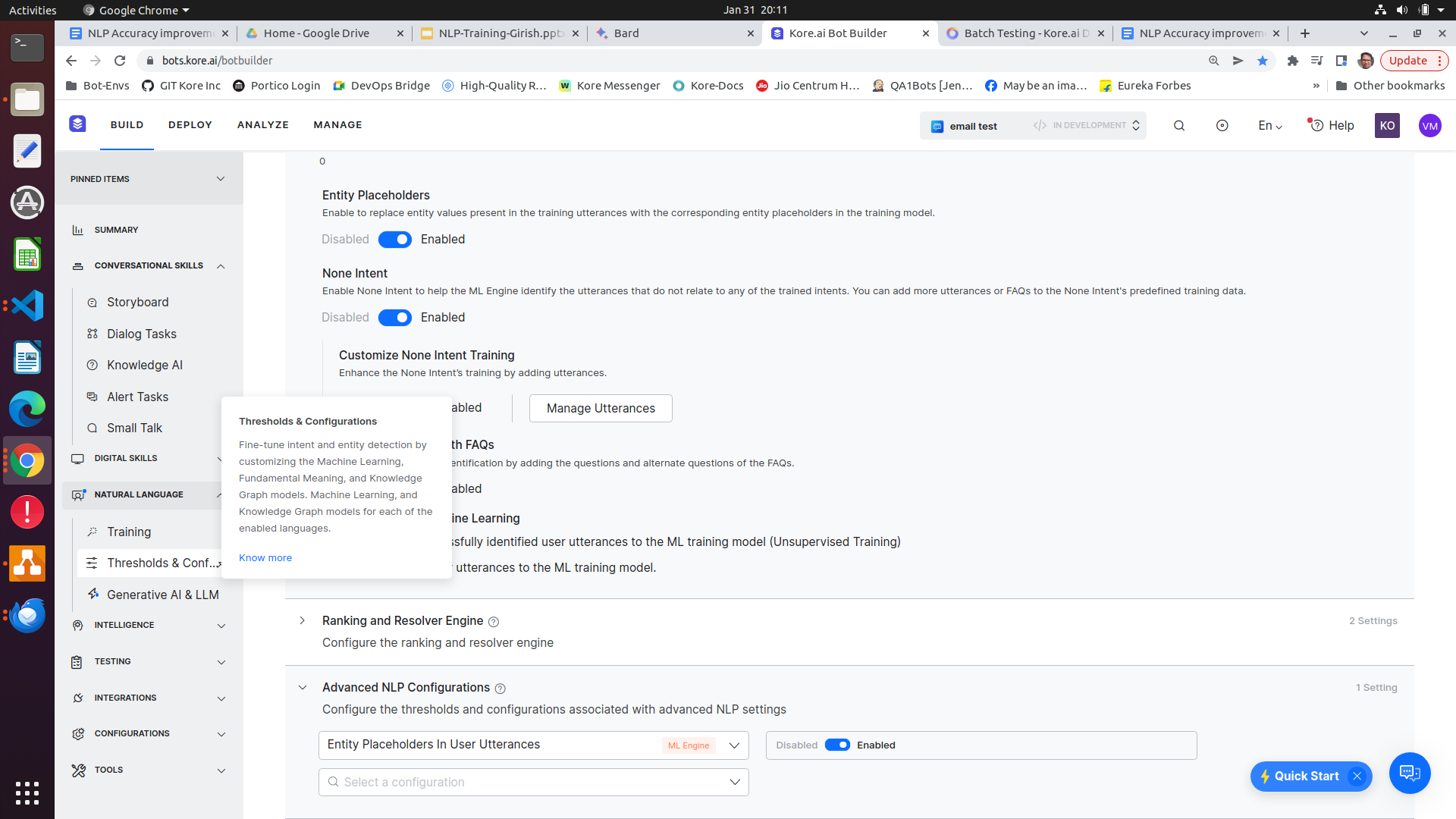
Entity placeholders is set to True in this bot (i.e., the NER-tagged words in the ML train data are replaced with the entity name and those words will be trained)
The NER confidence score is set to 0. (i.e., if we give some JUNK inputs also NER may identify) and that word will be replaced with the tagged entity name in the runtime.)
Now ML engine will identify as definitive matches for junk values.
- For ML Advanced embedding based networks, ML engine may not identify the right matched training utterance for the given input. Hence it is suggested to explore the options of disabling the re-scoring and proximity thresholds settings.