Hi
I’ve added an FAQ intent that reads:
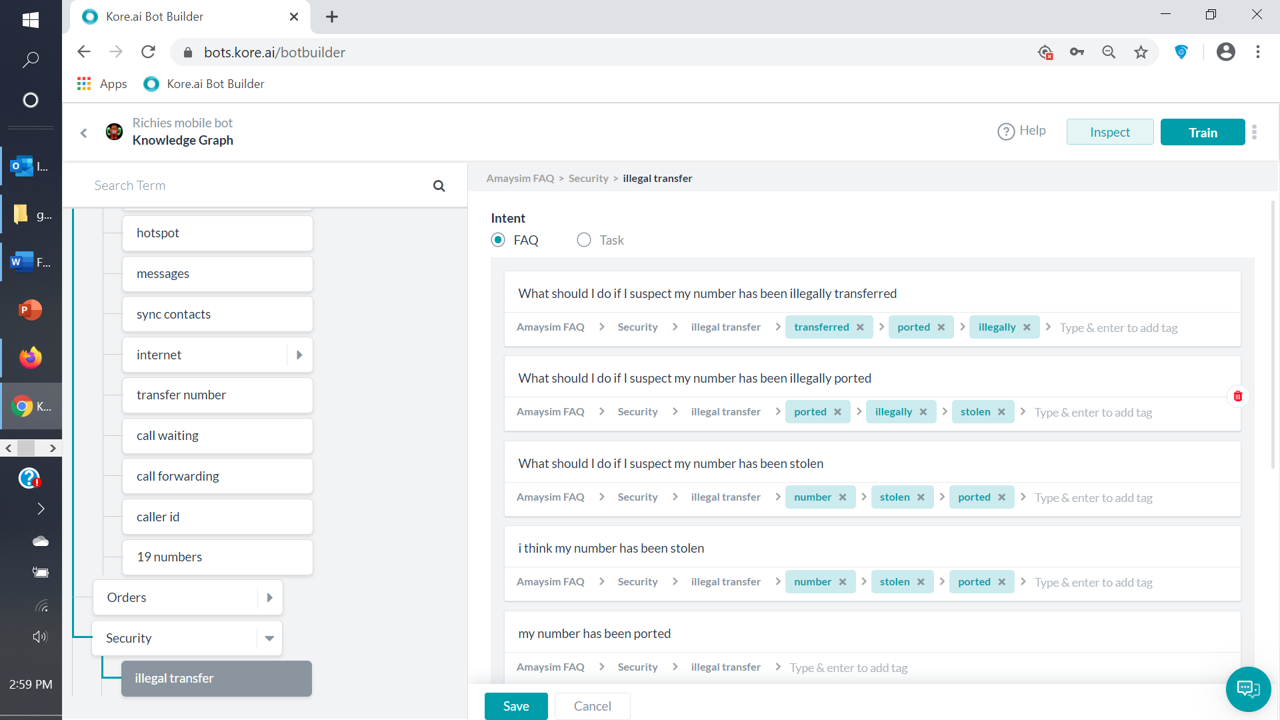
“What should I do if I suspect my number has been illegally transferred”
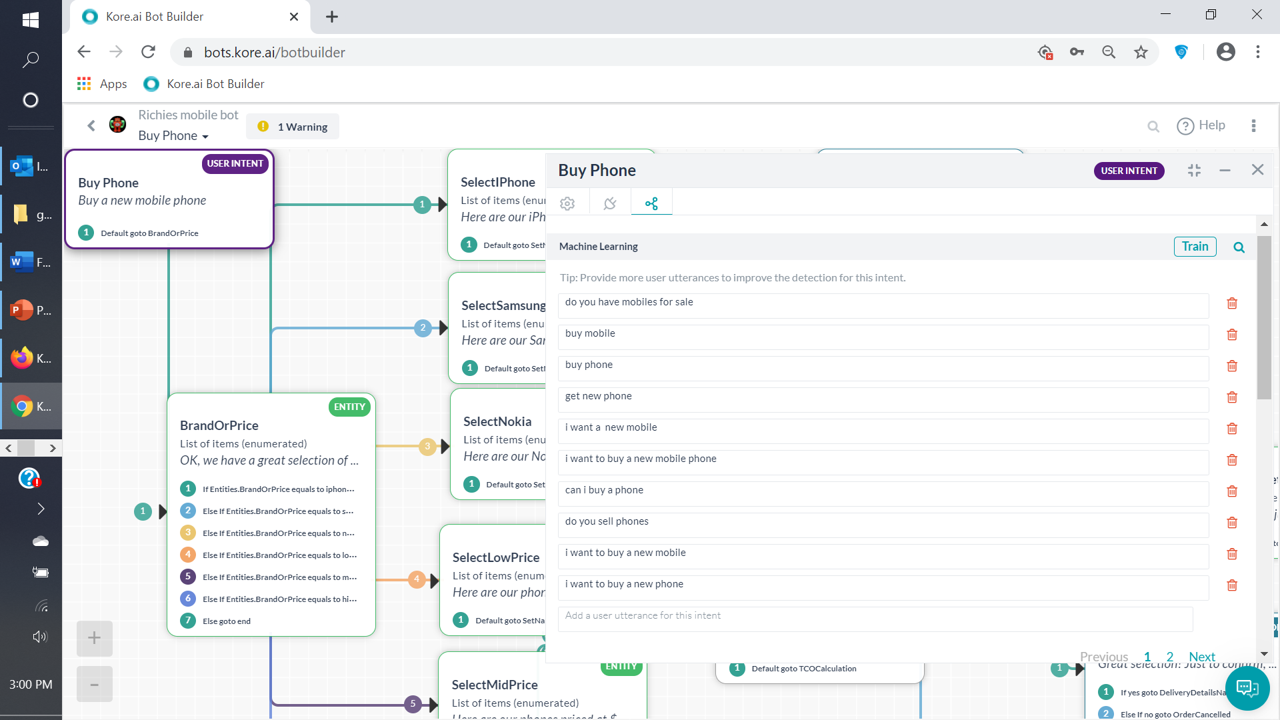
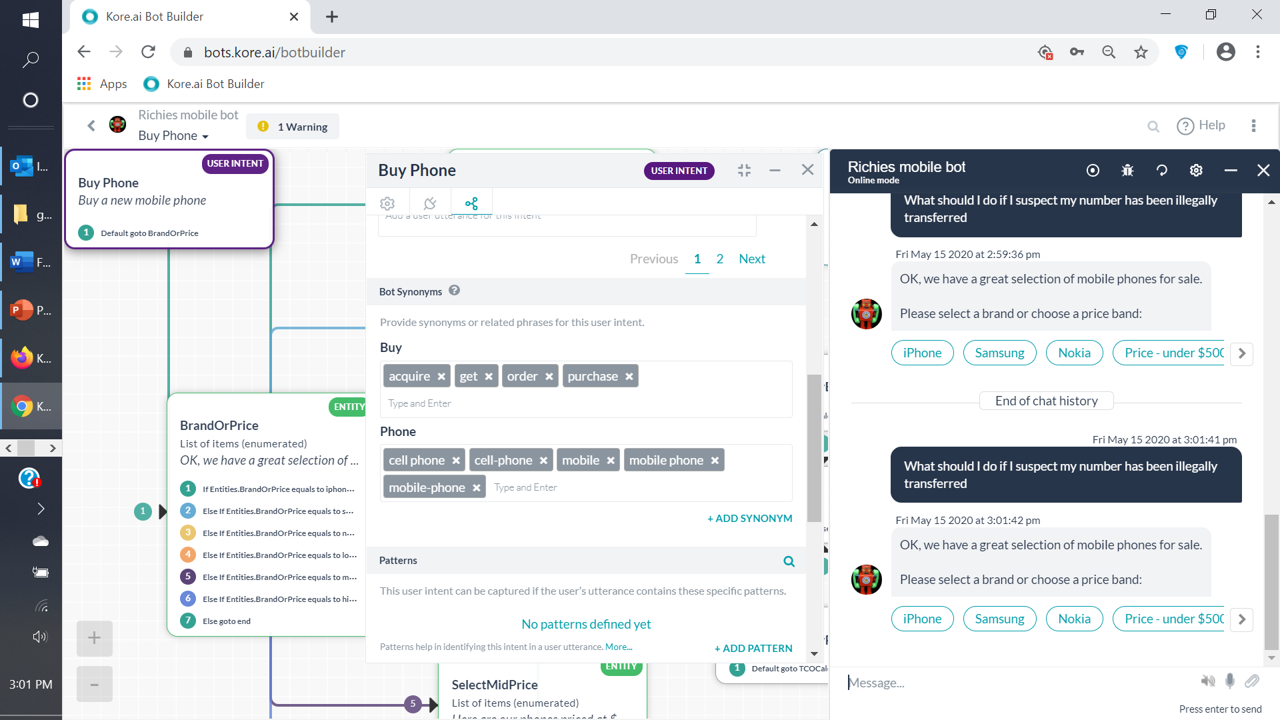
However, the NLP matches this to a Dialog (“buy phone”) - very different intents here. In fact, none of the alternative questions for the FAQ question here are getting the FAQ answer when I enter them in the bot.
For clarity, none of the words used in the FAQ match to anything in the Dialog intent. Also, there are no synonyms that are common to the FAQ or the Dialog. I’ve trained the bot for the FAQ.
I’ve attached screenshots of the config for the FAQ and Dialog, plus the results of the utterance test.
Can you please help me understand why the bot won’t match the correct intent for the FAQ, or work for any of the alternative questions?
thanks
Richard
Hi @richard_aus,
With the snap shot provided, its difficult to figure out the issue. However, I can guide you to debug the problem:
-
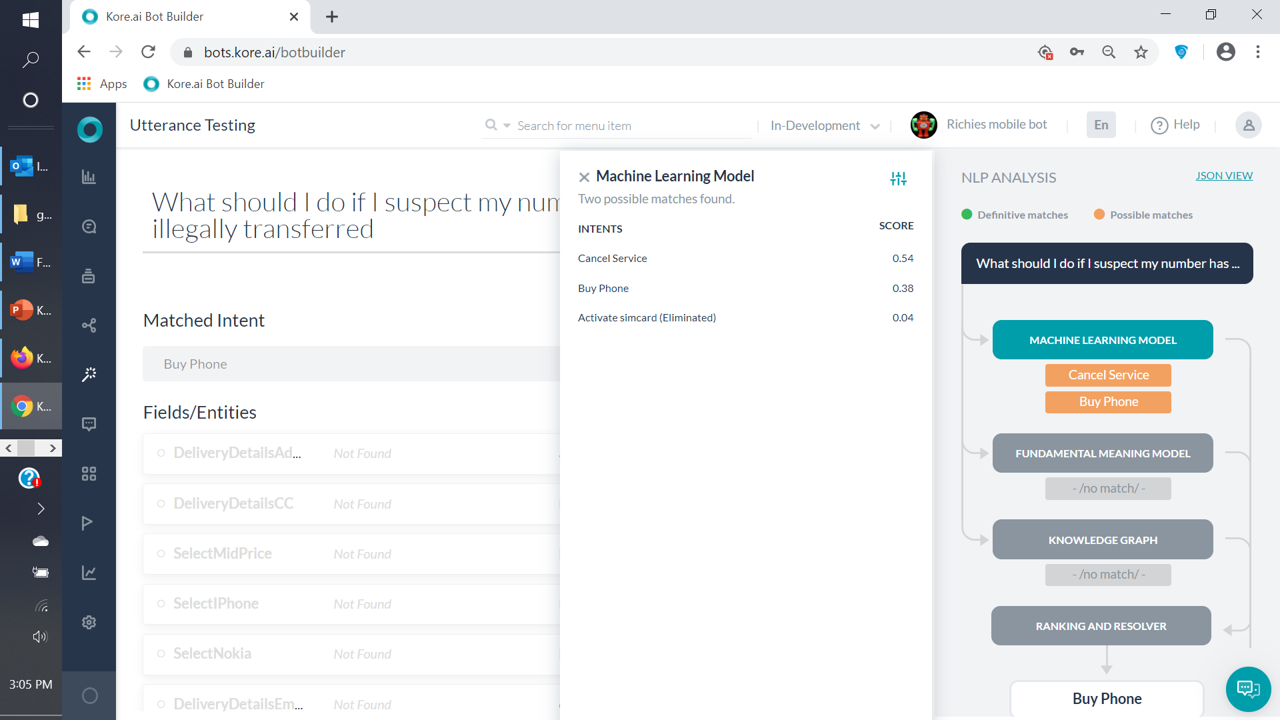
In the ‘Utterance Testing’ screen above, click on ‘Ranking & Resolver’. There it will show engine which identified the intent/FAQ. That can be either Machine learning (ML), Fundamental meaning (FM) or FAQ
-
According go to the respective section in NLP analysis screen and you can easily figure out the culprit.
Hope this should help!!!
From the utterance testing then you can see the KG is not considering any question to be relevant. So the ranking and resolvers only option is to go with the ML match.
The first step in the KG is to identify potential questions that have sufficient matching tags and terms in the path to the utterance. This is independent of the actual text in the question, so it is vitally important to pay attention to the words in the ontology nodes and the additional tags added to each question. The default is 50% coverage, so at least half of the tags and terms need to be present in the utterance for the KG to put the question on to a short list for further evaluation. For 5 terms, that means that at 3 must match.
If a question does not make that short list then it doesn’t matter if the words in the question match the utterance exactly or not. The question has already been discarded from consideration.
The second phase of the KG processing is to evaluate each of the short listed questions to see how similar the text of the question is to the utterance. This process generates a percentage score, and there are several thresholds that control how strict or lenient you want the bot to be. One debugging tip for earlier KG development is to move the minimum (orange) level for knowledge tasks all the way down, say 5%. This will allow more diagnostic information to be available in the Utterance Testing page on the Knowledge Graph box.
Now I can’t tell what synonyms you may have defined for the various tags and terms for your questions, but at first blush then “Security” looks like it is not contributing anything, and maybe not “ported”. I would also be very careful with multi word ontology nodes, they can be a little tricky.
Another tip, if you are always adding the same word as a tag to a question then it is likely to be a good candidate to be part of the ontology instead so that you can save yourself some effort and simplify the synonym maintenance.