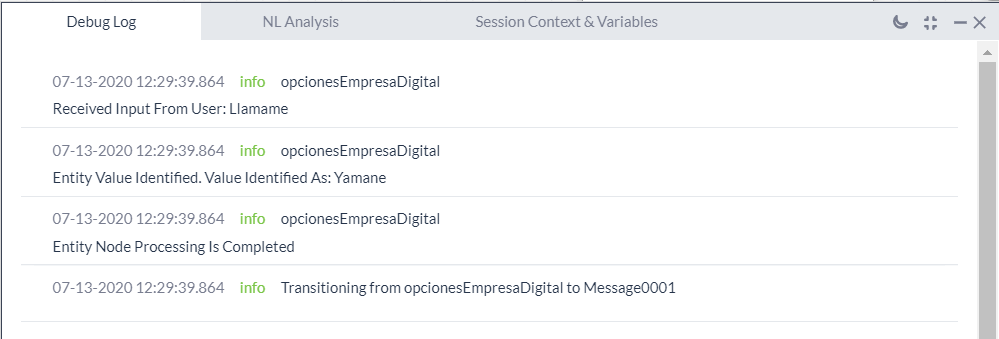
Hello team, i am working with a bot and have a really urgent issue that is not letting me send my bot to QA for publishing, here is the issue:
I am using several list entities on my bot, and they are behaving incorrectly, the list is configured using a sample template to create my options, when i try my flow, the debug log of the bot is showing me diferent results for data taken from input and data sent to the bot for processing. in one example, i have my list set up to send the value llamame, on the bot log i see the input correctly, but when it is processing the input, it is using the word Yamane, this is causin the bot to fail because it is not getting the correct input. This is happening in several occasions on my bot with different words .
I need to understand first, why is it changing the input text and the processed text, first i assumed it was the autocorrect feature, so i turned it off, but now i cant process the word Llamame a llamame, since the autocorrect puts in the capital L.
Second, how do i configure sinonyms using a template for a list, i dont see any parameter that could be used as sinonyms. I tried inspecting the template but its not showing the structure as it is.
This error has been happening since late last week, previously, it was working as intended
As part of the standard NLP pipeline, all user utterances go through a series of steps to identify POS tags and to do some spell correction. This is entirely independent of any entity.
The spell correction is done based on a dictionary for the language which is comprised of a (very large) internal dictionary and any additional words defined in the Synonyms and Concepts NL panel.
“llamame” doesn’t appear to be part of the standard dictionary and therefore is a candidate for being corrected, to Yamane (which is a person name).
The solution is to therefore extend the bot’s dictionary by using this word in a concept. That makes the word known the the NLP pipeline and so it is not corrected. It doesn’t matter what the concept is called, it is just the presence of the new word in a concept that helps.
Now the autocorrection setting for a list of values entity is a secondary correction processing that only applies when that entity is processed. Because choices can be dynamic, and the words used as the synonyms are not visible to the initial NLP pipeline, then there is an additional correction process where each word in the utterance is checked as a potential correction give the new knowledge of the significant words. However there is a threshold of whether a word is changed or not, and also assumes that the first character is the same. So this is preventing the correction at the entity.
Hi @andy.heydon , could you confirm if this behavior is expected with a “String entity” (Just confirming as I think the above comment may be specific to LoV) with “Do not auto-correct setting”?
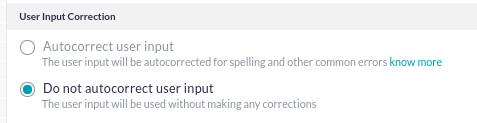
When using the above setting in German language the entity is correcting some of the strings for example :
schlos --> Schluss
faum --> kaum
qwer --> query
Although using these strings as synonyms anywhere in the bot will not autocorrect.
@swagata.sengupta @simon.vogt
No, it is supposed to return the raw original input, not anything that has been spell corrected. This looks like a bug in that the data is being pulled from the wrong variable.