I created a concept and used it in the patterns of trait. I added that trait in the KG node. It is showing that a trait is added but the trait is not hit when I talk to the bot. Can somebody please help?
There is not enough information to describe why something is not hit.
Traits are an independent and standalone technique for identifying stuff from a user’s utterance. The traits engine is the first one to be run in the NL pipeline and all it does is find potentially interesting elements given the training. There is no explicit commitment to use the identified traits.
But one place where they can be used as an qualifier within KG. When a trait name is connected to a KG node then it means that for the underlying questions to be considered, then this trait MUST have been identified from the user’s utterance. Doesn’t matter if the question is otherwise a perfect match.
So your first step is to determine whether the trait “is a service free” is actually identified for the user’s utterance. You haven’t provided the utterance or details of the trait training, so I cannot comment further.
The next step is to determine whether the KG training is sufficient to match the user’s utterance. Again there is not enough information to provide a more detailed answer. But you can diagnose that independently by removing the trait name from the node settings, retraining the KG and testing the utterance again.
But what I can say is the identification of a KG question is a two step processing. First a list of questions that meet the path matching threshold are identified, and from that list the “closest” question is calculated. Therefore path matching is typically the most important step.
Each question has a “path” derived from the terms and tags implicitly and explicitly defined, which are the important words for that question, the words that control the understanding. The default threshold is that half of those path terms/tags have to be present in the user’s utterance. Failure to meet that threshold will mean the question is not passed on to the second phase for detailed scoring. It is often counter productive to add lots of individual tags to a question because that makes it harder to meet the threshold. Too few terms can mean more false positives and ambiguities.
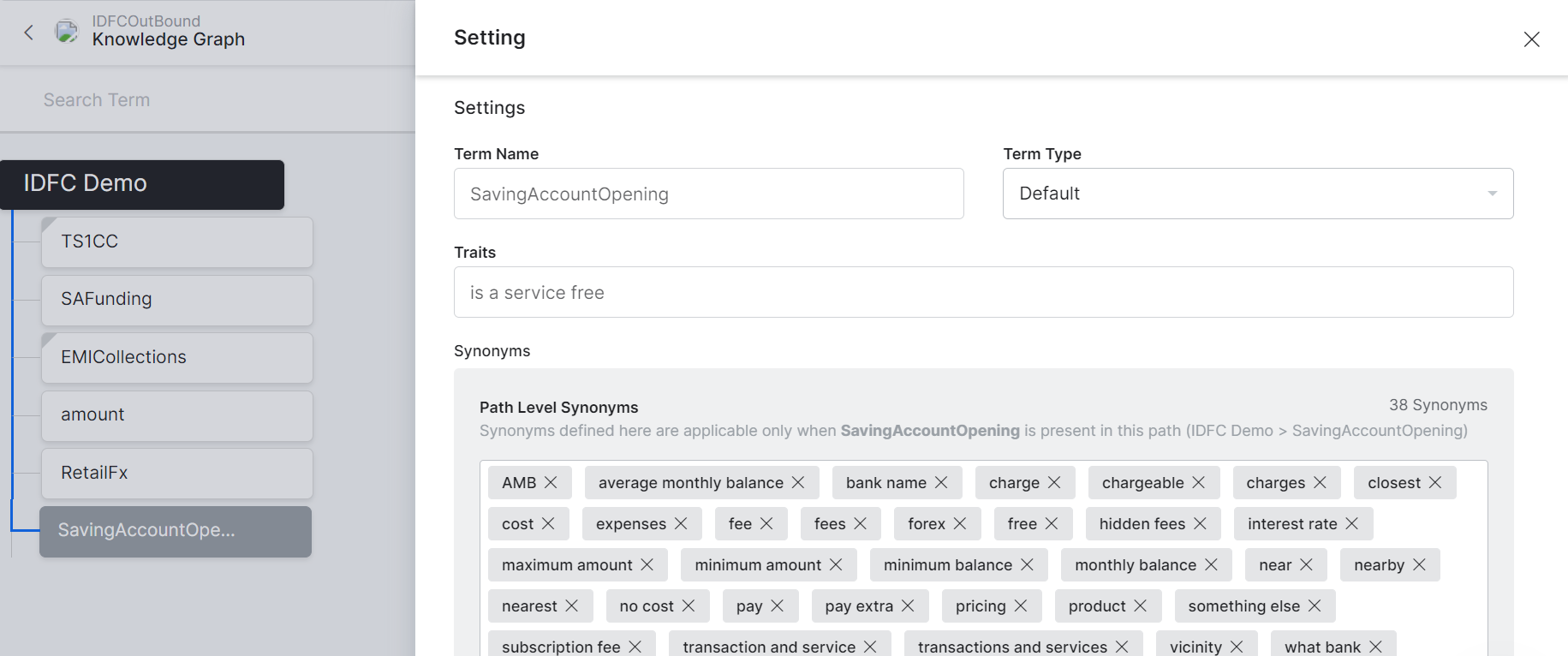
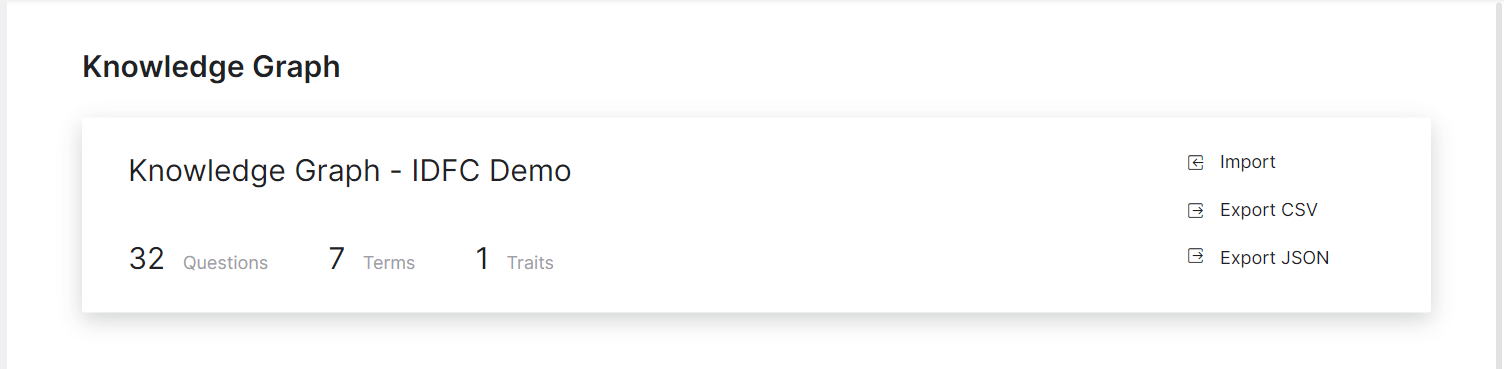
The one thing that we can see in the screenshot raises a red flag though. 38 path level synonyms for a single term is a signal of poor or insufficient training. My guess, given that there are only 7 terms across 32 questions, is that you’ve overloaded the path synonyms instead of using more nodes and assigning relevant tags to each question.
A synonym is a word or phrase that has the same meaning as another. In the world of NL training this means that each of the words in a synonym list can be used interchangeably. The quick test for this is that all of the words in the set should be the same part of speech - in a sentence, a verb cannot be replaced with an adjective, you cannot “nearest a bill.” Another test is to take a sentence, replace the synonym with the other word and make sure it still makes sense when reading it. If sounds wrong then it is not a synonym.
The screenshot list includes nouns, verbs, adjective and adverbs. It should be obvious that those words are not interchangeable.
1 Like