I set up the custom type of an entity with this regex: ^\w{7}$. It works fine with an input of 7 digit (eg. 1234567) or a combination of numbers and letters (eg. 1QWERTY), but for some reason it raise an error when I input a value with this pattern: 2 digit + ZX + 3 digit (eg. 88ZX123 or 99ZX321). What is the reason of this issue and how to fix it?
@francesco.velocci I have tested the issue from my side and there seems to be a problem with regex somehow at the entity type “custom”. I’ll check with the development team on this.
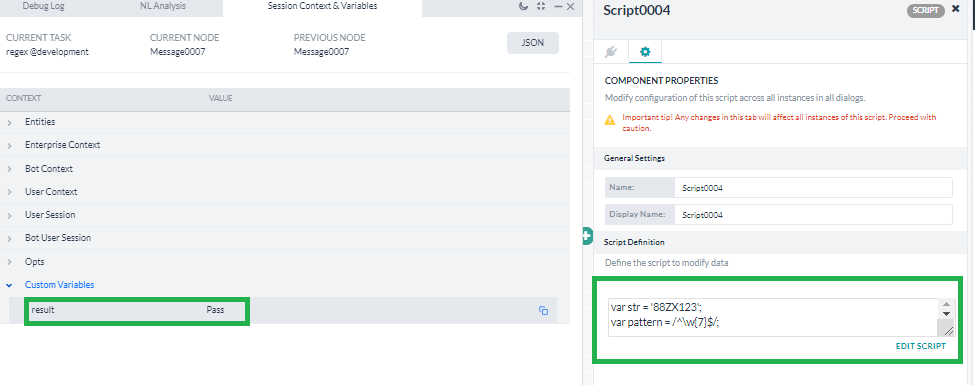
I have used the same regex at script node and tried to update a context variable depending on the string matches regex pattern. Below is the code snippet.
var str = '88ZX123';
var pattern = /^\w{7}$/;
var res = str.match( pattern );
if(res){
context.result="Pass";
}else{
context.result="Fail";
}
Below is the snapshot showing that context.result is updated based on the logic at the script node.
Now depending on “context.result”, lets say, applying a transition condition context.result = Fail, you could show an error message to the user using a message node, delete the entered user input at Entity node using script node (delete context.entities.entity) and transition the user back to the Entity node for entering the user input again.
The thing to remember with the regex, and indeed all NL processing, is the the basic unit of work is the word, and that a word is something that is generally space separated (there are exceptions to that but spaces are the general case).
The custom entity with a regex is therefore matching words, and given that you have no control over what a user may type, all regex patterns are automatically wrapped in \b tokens to enforce that word boundary.
That also means that the start and end of line tokens, ^ and $ should not be present in the regex.
Now to this specific example, the issue comes from how 88ZX123 is parsed by NL engine. There is some code that takes an input like “2x4” and splits into three words “2 x 4” - i.e. “two by four” - because that is a fairly general expression and it is desirable to be able to get at those numbers individually. This is one of those word boundary exceptions mentioned above.
Thank you for the explanation. I would just to point out that the pattern <2digit + ZX + 3digit> generates an error handled whithin the entiy, while the pattern <2digit + X + 4digit>, generate a server error. Anyway I understand the need for NLP to prioritize actual words over combinations of digits and letters, but sometimes there are good reasons to validate an input (that could be a code: for example a ticket number) client side before call a web service.
I am using custom type in entity node for Regex to allow only alphabets (a-zA-Z).
Could you please provide the exp here I am facing issue.
Thanks