Having just a bit of trouble forcing the ML to return the digit when the text name is returned from the NLU. Voice users might say, for example, 1 2 3. The NLU returns One, two, and three but our application needs the actual numerical representation of each digit. Any suggestions?
Have you tried numeric entity type with entity rules?
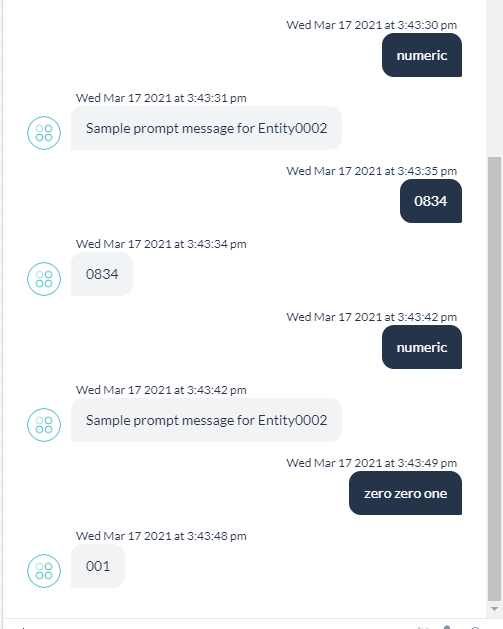
This should work in v8.1 and latest v8.0.x patch
Hi Swagata and thanks for responding. Firstly, our company is still on version 7.3 which is failing in several scenarios. At the moment, though, I am concerned only over this one.
Yes, I have set that node as a numeric type and you are correct. It does work. Actually, it works a bit to aggressively. There is another Entity, this one is hidden, that collects Zip Code. Allow me to provide a sample utterance. “Please find a doctor within 5 miles of 32408.” I set the “zipcode” entity to type zipcode but that fails completely. We then set zipcode to type “custom” with a regex designed to capture U.S. Zip Codes. That did indeed collect the zipcode…until we set the “miles” entity to type “numeric”. It then grabbed the zip code all of the time. So we then set the “miles” entity to type “custom” including a regex designed to isolate and grab only numbers of 4 or fewer digits. This is where the issue of the entity returning the text value of the number such as returning “eight” and even “ate”. The return from 30208 zip code was actually captured as 3 to oh 8. The regex, which I know to be correct, did not filter this 5 digit “number” and placed its output into the “miles” slot.
Michael,
Zip codes are a thorny problem because from a global perspective most formats are just simple numbers, sometimes from as few as 3 digits. Currently in the initial utterance we only look through a small set of “strict” zip codes that cannot be easily confused such as codes that require letters and numbers like Canada and the UK. It is not ideal, but it reduces the number of false positives greatly. Though the platform if it can determine a country from the utterance, will use that country’s zip code regex in an attempt to find numbers.
But what you can do is help guide the platform in identifying an entity.
The major one is using an entity rule for the zip code to list the preferred countries for it. The platform will then know which formats are OK to look for.
This is not documented for r7.3 but it should work because the specific code was added well before that release. Have a script node before the zip code entity with something like:
context.entityRules = {
"<zipcode entity name>" : {
"preferredCountries" : ["US"]
}
};
An additional clue can be to use entity patterns to describe the phrases that typically surround the entity value and which suggest to the platform where to start looking, even in the initial utterance.
So for the zip code entity, a pattern like: “mile of *” would be a big clue, and help if some-one crazily says “find a doctor within 10000 miles of 32408”.
Now you should use concepts instead of simple words to cover different distance units and different prepositions.
1 Like